YOLOv3 算法的一点理解
今天讲一讲 YOLOv3, 目标检测网络的巅峰之作, 疾如风,快如闪电。

1. 算法背景
假设我们想对下面这张 416 X 416 大小的图片进行预测,把图中 dog、bicycle 和 car 三种物体给框出来,这涉及到以下三个过程:
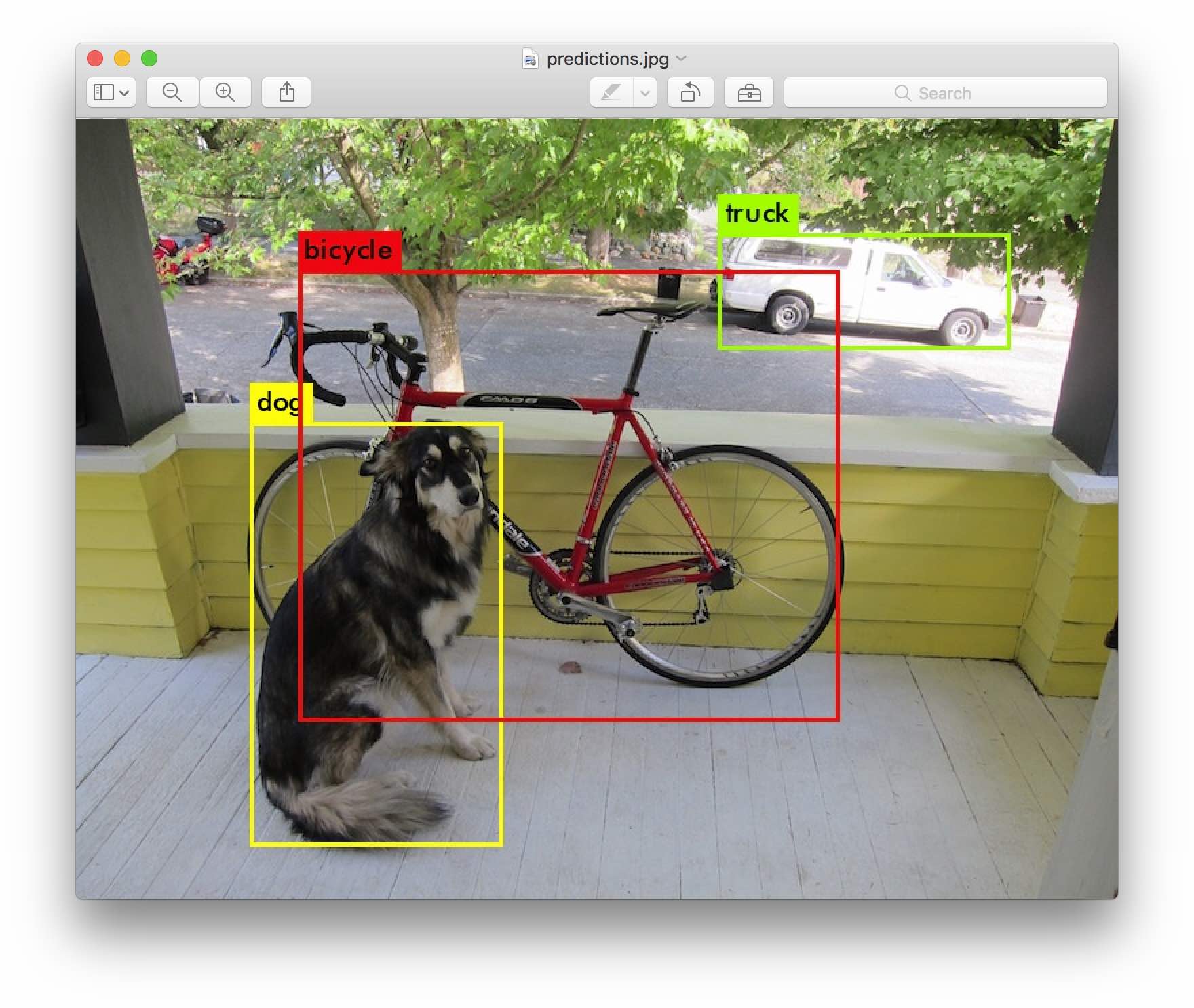
- 怎么在图片上找出很多有价值的候选框?
- 接着判断候选框里有没有物体?
- 如果有物体的话,那么它属于哪个类别?
听起来就像把大象装进冰箱,分三步走。事实上,目前的 anchor-based 机制算法例如 RCNN、Faster rcnn 以及 YOLO 算法都是这个思想。最早的时候,RCNN 是这么干的,它首先利用 Selective Search 的方法通过图片上像素之间的相似度和纹理特征进行区域合并,然后提出很多候选框并喂给 CNN 网络提取出特征向量 (embeddings),最后利用特征向量训练 SVM 来对目标和背景进行分类。

这是最早利用神经网络进行目标检测的开山之作,虽然现在看来有不少瑕疵,例如:
- Selective Search 会在图片上提取2000个候选区域,每个候选区域都会喂给 CNN 进行特征提取,这个过程太冗余啦,其实这些候选区域之间很多特征其实是可以共享的;
- 由于 CNN 最后一层是全连接层,因此输入图片的尺寸大小也有限制,只能进行 Crop 或者 Warp,这样一来图片就会扭曲、变形和失真;
- 在利用 SVM 分类器对候选框进行分类的时候,每个候选框的特征向量都要保留在磁盘上,很浪费空间!
尽管如此,但仍不可否认它具有划时代的意义,至少告诉后人我们是可以利用神经网络进行目标检测的。后面,一些大神们在此基础上提出了很多改进,从 Fast RCNN 到 Faster RCNN 再到 Mask RCNN, 目标检测的 region proposal 过程变得越来越有针对性,并提出了著名的 RPN 网络去学习如何给出高质量的候选框,然后再去判断所属物体的类别。简单说来就是: 提出候选框,然后分类,这就是我们常说的 two-stage 算法。two-stage 算法的好处就是精度较高,但是检测速度满足不了实时性的要求。
在这样的背景下,YOLO 算法横空出世,江湖震惊!
2. YOLO 算法简介
2.1 发展历程
2015 年 Redmon J 等提出 YOLO 网络, 其特点是将生成候选框与分类回归合并成一个步骤, 预测时特征图被分成 7x7 个 cell, 对每个 cell 进行预测, 这就大大降低了计算复杂度, 加快了目标检测的速度, 帧率最高可达 45 fps!
时隔一年,Redmon J 再次提出了YOLOv2, 与前代相比, 在VOC2007 测试集上的 mAP 由 67.4% 提高到 78.6%, 然而由于一个 cell 只负责预测一个物体, 面对重叠性的目标的识别得并不够好。
最终在 2018 年 4 月, 作者又发布了第三个版本 YOLOv3, 在 COCO 数据集上的 mAP-50 由 YOLOv2 的 44.0% 提高到 57.9%, 与 mAP 61.1% 的 RetinaNet 相比, RetinaNet 在输入尺寸 500×500 的情况下检测速度约 98 ms/帧, 而 YOLOv3 在输入尺寸 416×416 时检测速 度可达 29 ms/帧。
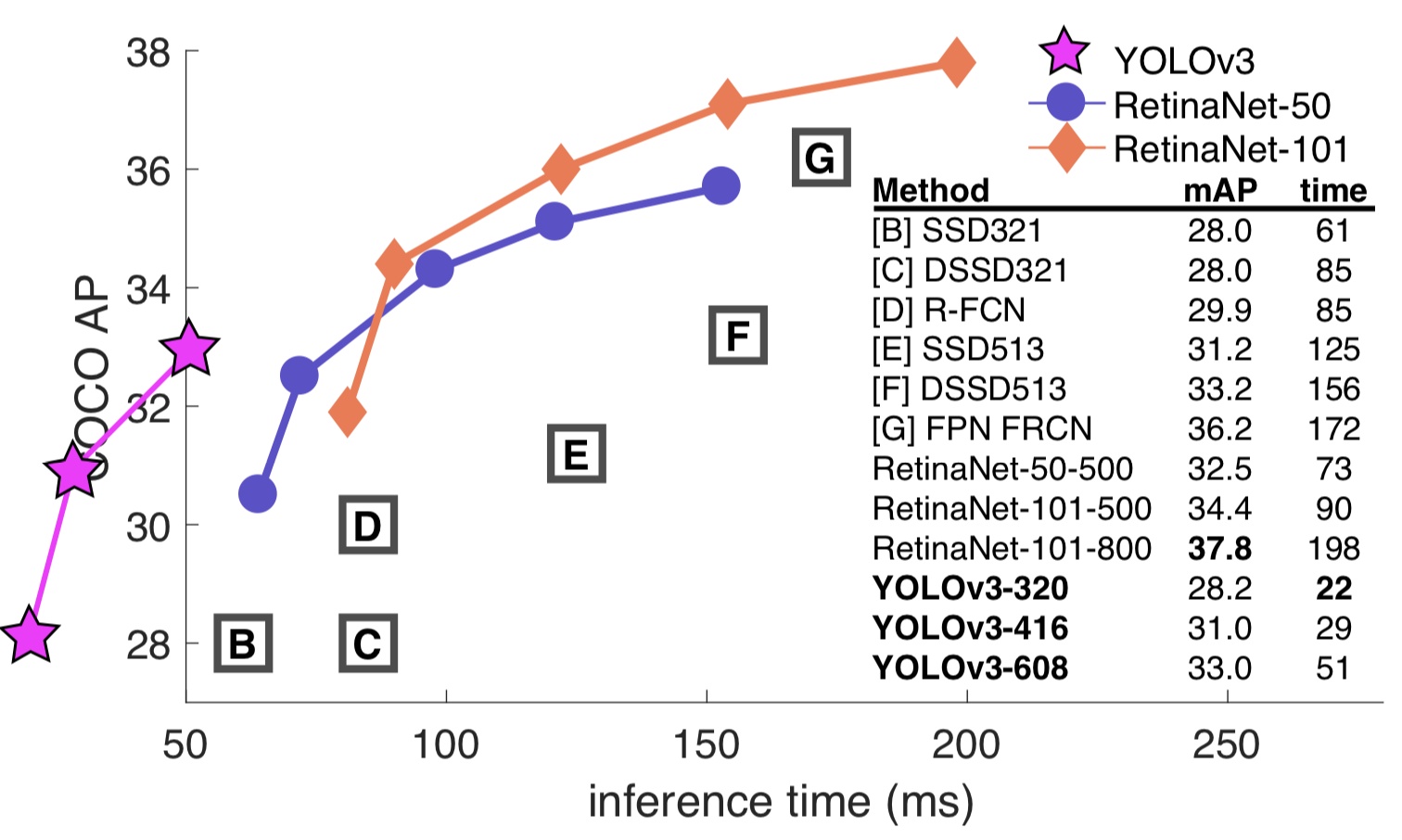
上面这张图足以秒杀一切, 说明 YOLOv3 在保证速度的前提下, 也达到了很高的准确率。
2.2 基本思想
作者在YOLO算法中把物体检测(object detection)问题处理成回归问题,并将图像分为S×S的网格。如果一个目标的中心落入格子,该格子就负责检测该目标。
If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
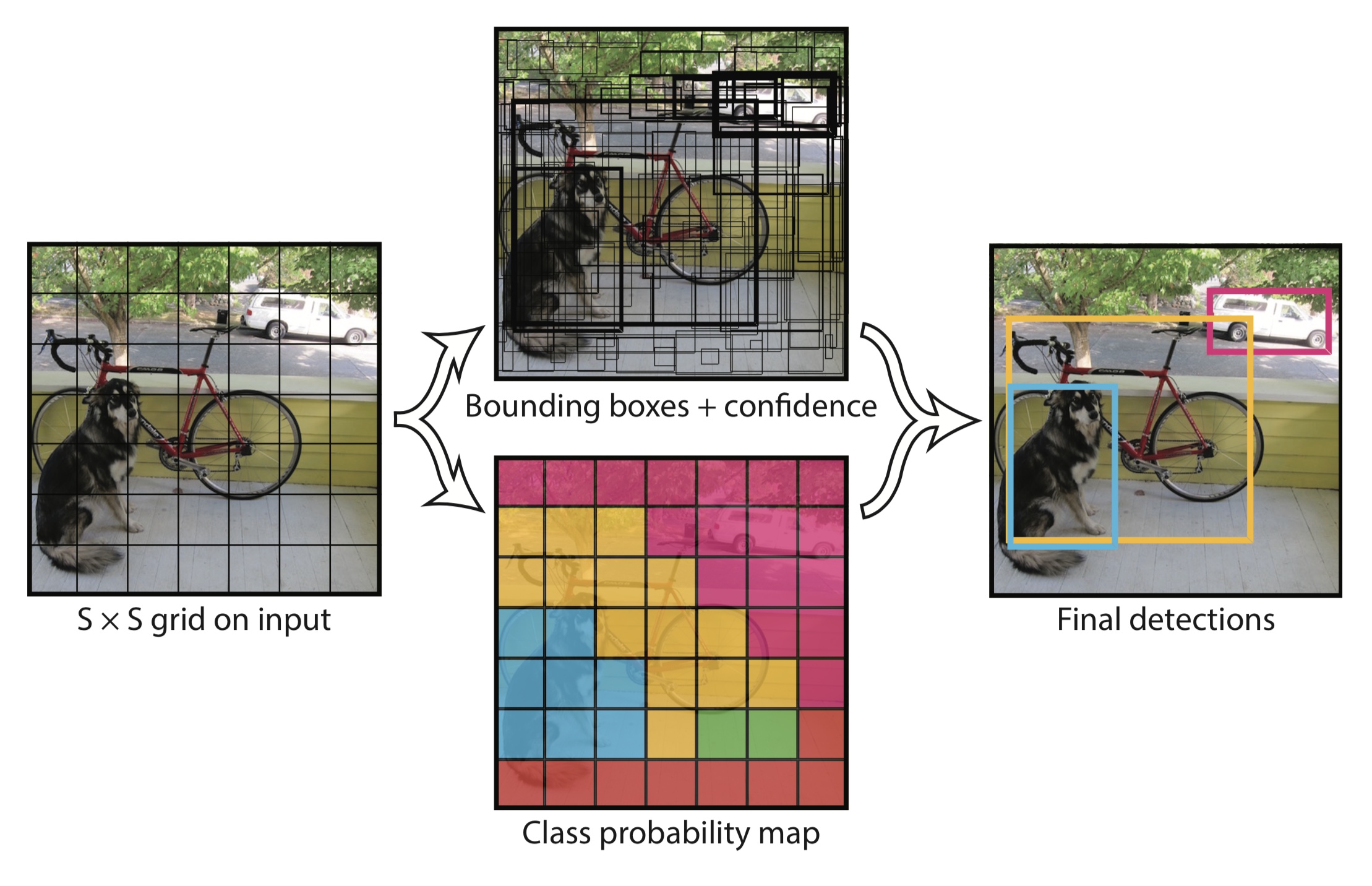
每个网格都会输出 bounding box,confidence 和 class probability map。其中:
- bounding box 包含4个值:x,y,w,h,(x,y)代表 box 的中心。(w,h)代表 box 的宽和高;
- confidence 表示这个预测框中包含物体的概率,其实也是预测框与真实框之间的 iou 值;
- class probability 表示的是该物体的类别概率,在 YOLOv3 中采用的是二分类的方法。
3. 网络结构
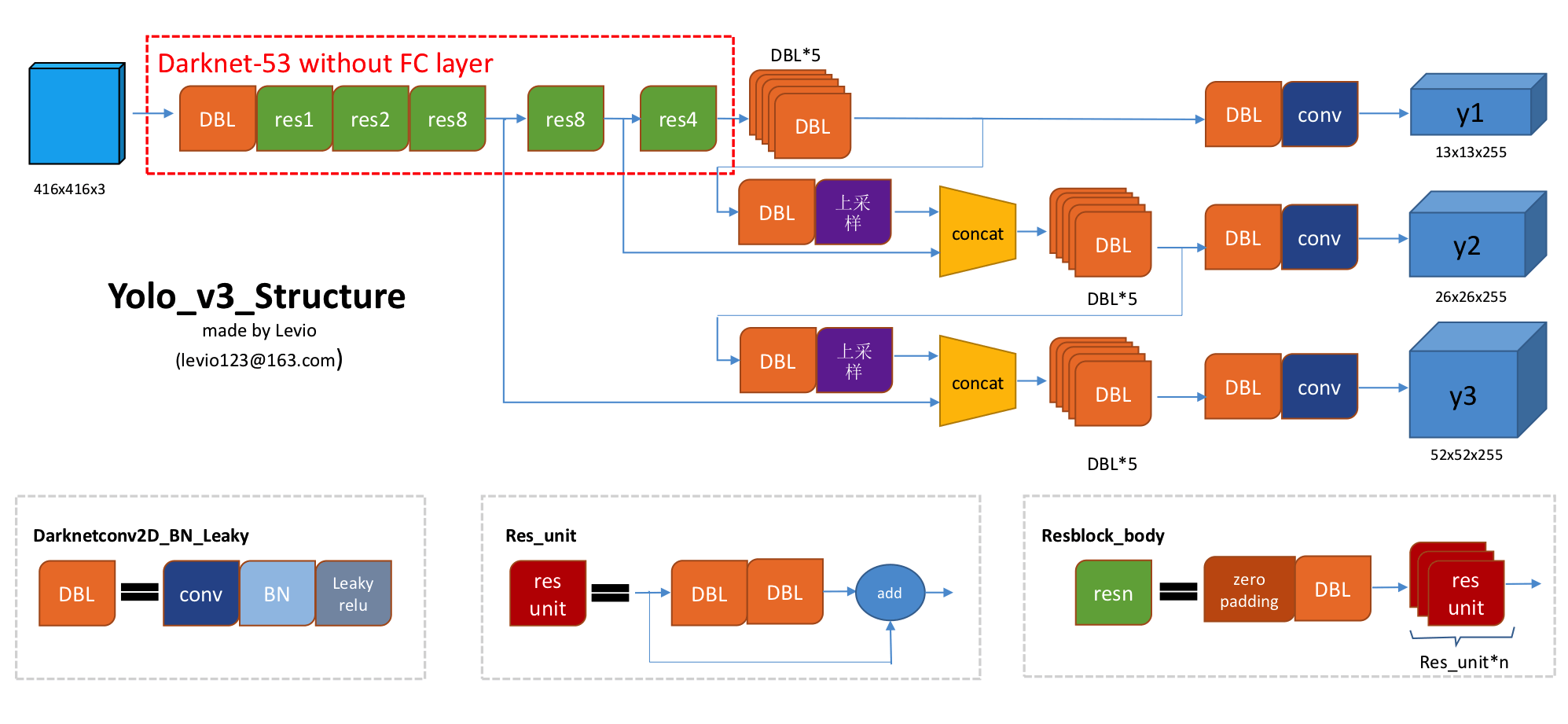
下面这幅图就是 YOLOv3 网络的整体结构,在图中我们可以看到:尺寸为 416X416 的输入图片进入 Darknet-53 网络后得到了 3 个分支,这些分支在经过一系列的卷积、上采样以及合并等操作后最终得到了三个尺寸不一的 feature map,形状分别为 [13, 13, 255]、[26, 26, 255] 和 [52, 52, 255]。
讲了这么多,还是不如看代码来得亲切。
def YOLOv3(input_layer): |
3.1 Darknet53 结构
Darknet-53 的主体框架如下图所示,它主要由 Convolutional 和 Residual 结构所组成。需要特别注意的是,最后三层 Avgpool、Connected 和 softmax layer 是用于在 Imagenet 数据集上作分类训练用的。当我们用 Darknet-53 层对图片提取特征时,是不会用到这三层的。
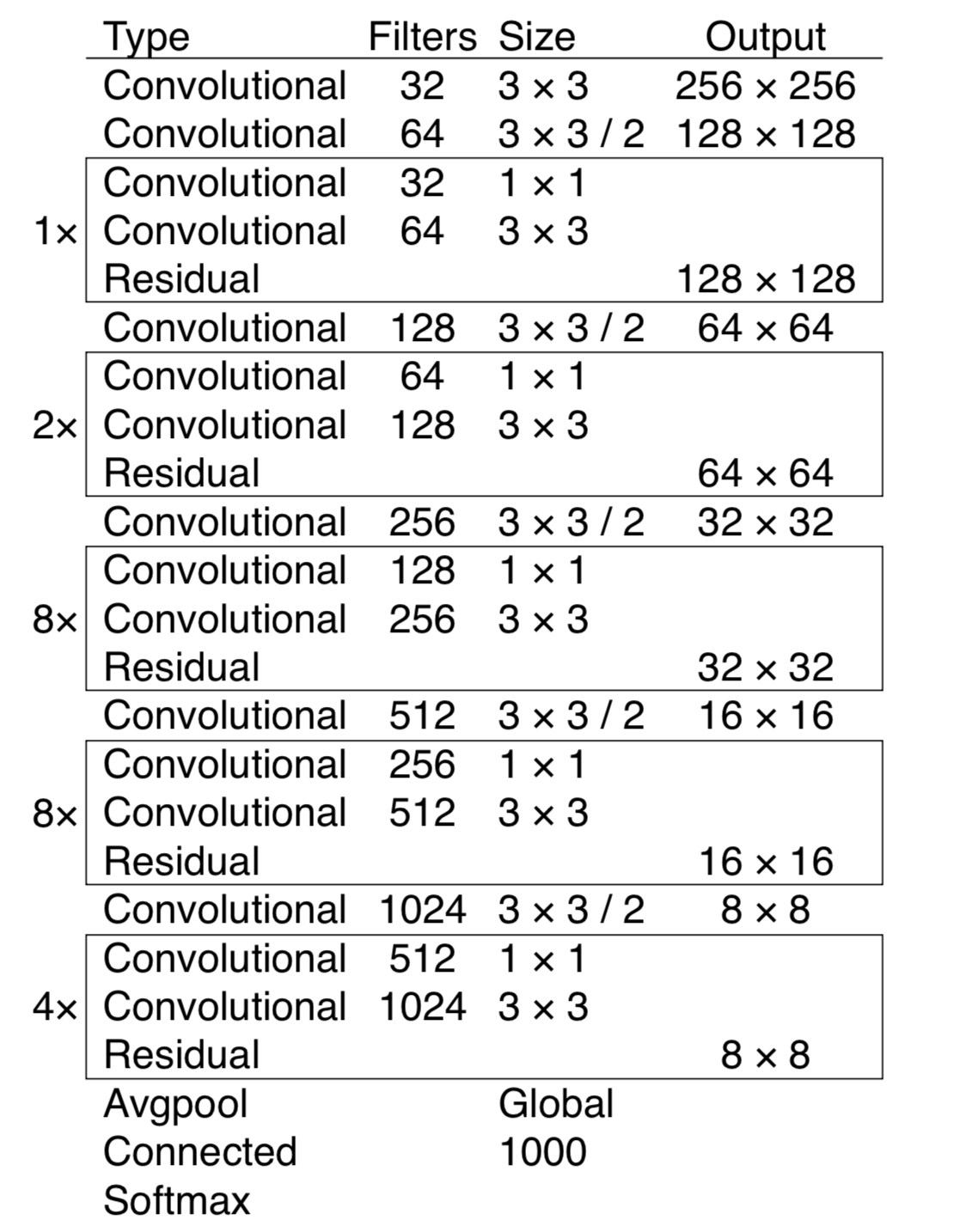
Darknet-53 有多牛逼?看看下面这张图,作者进行了比较,得出的结论是 Darknet-53 在精度上可以与最先进的分类器进行媲美,同时它的浮点运算更少,计算速度也最快。和 ReseNet-101 相比,Darknet-53 网络的速度是前者的1.5倍;虽然 ReseNet-152 和它性能相似,但是用时却是它的2倍以上。
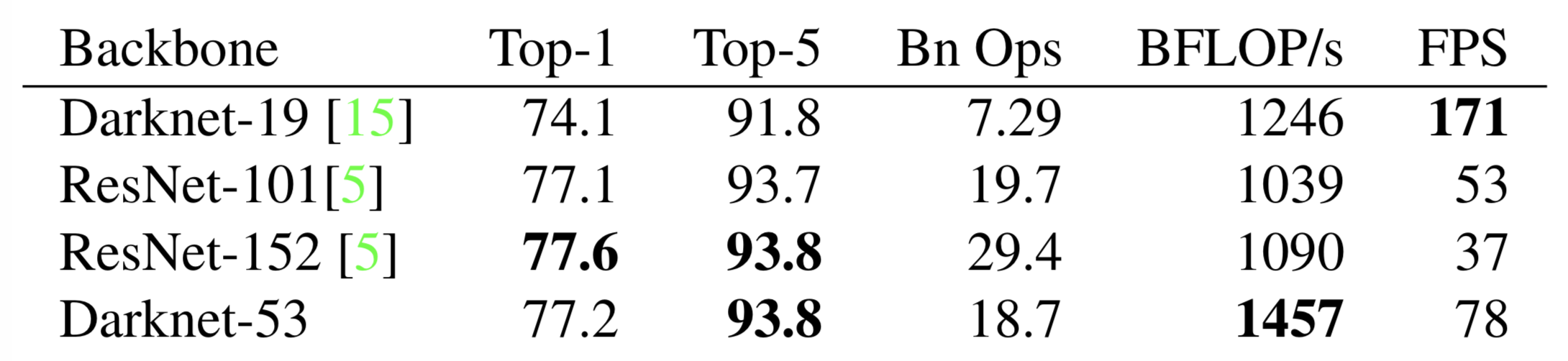
此外,Darknet-53 还可以实现每秒最高的测量浮点运算,这就意味着网络结构可以更好地利用 GPU,从而使其测量效率更高,速度也更快。
3.2 Convolutional 结构
Convolutional 结构其实很简单,就是普通的卷积层,其实没啥讲的。但是对于 if downsample 的情况,初学者可能觉得有点陌生, ZeroPadding2D 是什么层?
def convolutional(input_layer, filters_shape, downsample=False, activate=True, bn=True): |
讲到 ZeroPadding2D层,我们得先了解它是什么,为什么有这个层。对于它的定义,Keras 官方给了很好的解释:
keras.layers.convolutional.ZeroPadding2D(padding=(1, 1), data_format=None) 说明: 对2D输入(如图片)的边界填充0,以控制卷积以后特征图的大小
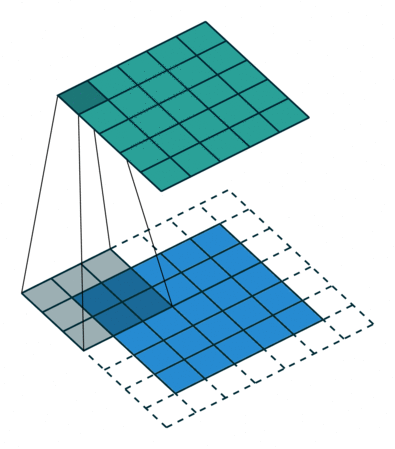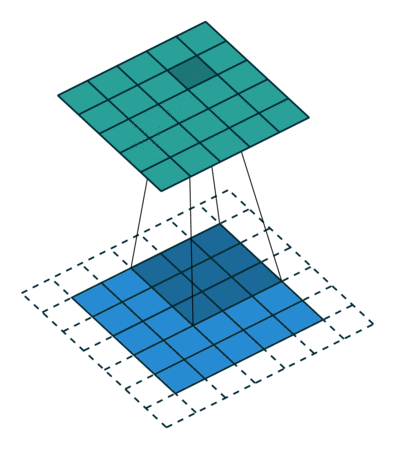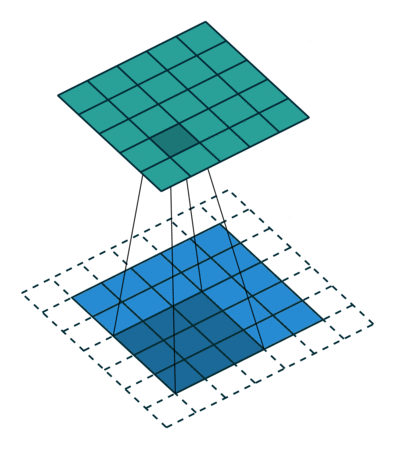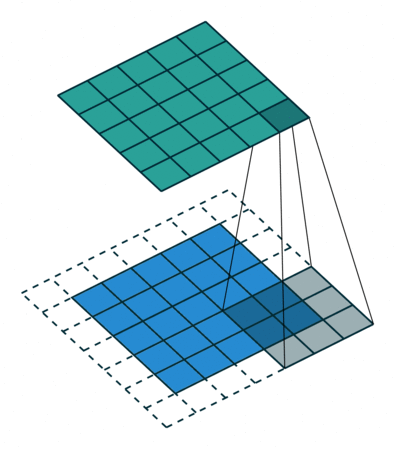
其实就是对图片的上下左右四个边界填充0而已,padding=((top_pad, bottom_pad), (left_pad, right_pad))。 很简单吧,快打开你的 ipython 试试吧!
In [2]: x=tf.keras.layers.Input([416,416,3]) |
3.3 Residual 残差模块
残差模块最显著的特点是使用了 short cut 机制(有点类似于电路中的短路机制)来缓解在神经网络中增加深度带来的梯度消失问题,从而使得神经网络变得更容易优化。它通过恒等映射(identity mapping)的方法使得输入和输出之间建立了一条直接的关联通道,从而使得网络集中学习输入和输出之间的残差。
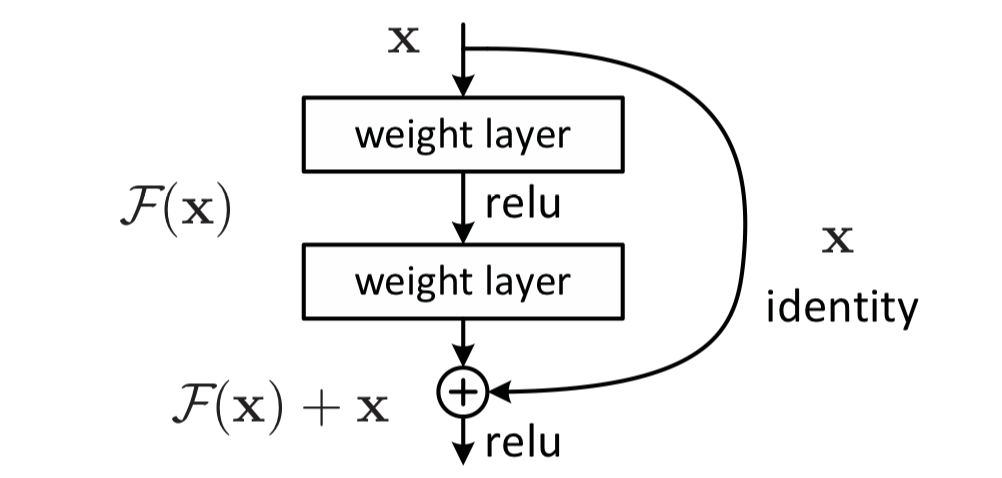
def residual_block(input_layer, input_channel, filter_num1, filter_num2): |
4. 提取特征
要想详细地知道 YOLO 的预测过程,就非常有必要先来了解一下什么是特征映射 (feature map) 和特征向量 (embeddings)。
4.1 特征映射
当我们谈及 CNN 网络,总能听到 feature map 这个词。它也叫特征映射,简单说来就是输入图像在与卷积核进行卷积操作后得到图像特征。
一般而言,CNN 网络在对图像自底向上提取特征时,feature map 的数量(其实也对应的就是卷积核的数目) 会越来越多,而空间信息会越来越少,其特征也会变得越来越抽象。比如著名的 VGG16 网络,它的 feature map 变化就是这个样子。
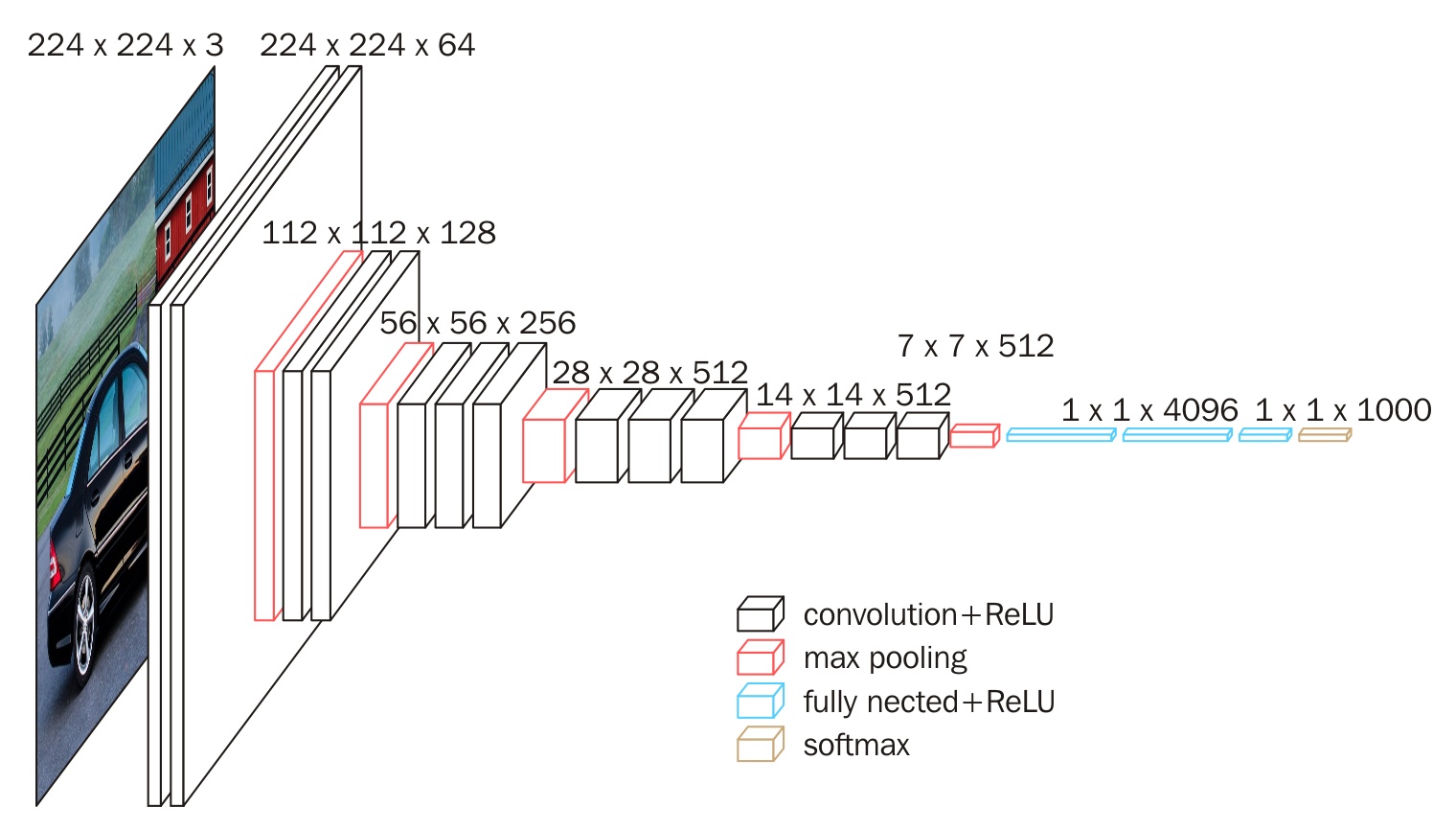
feature map 在空间尺寸上越来越小,但在通道尺寸上变得越来越深,这就是 VGG16 的特点。
4.2 特征向量
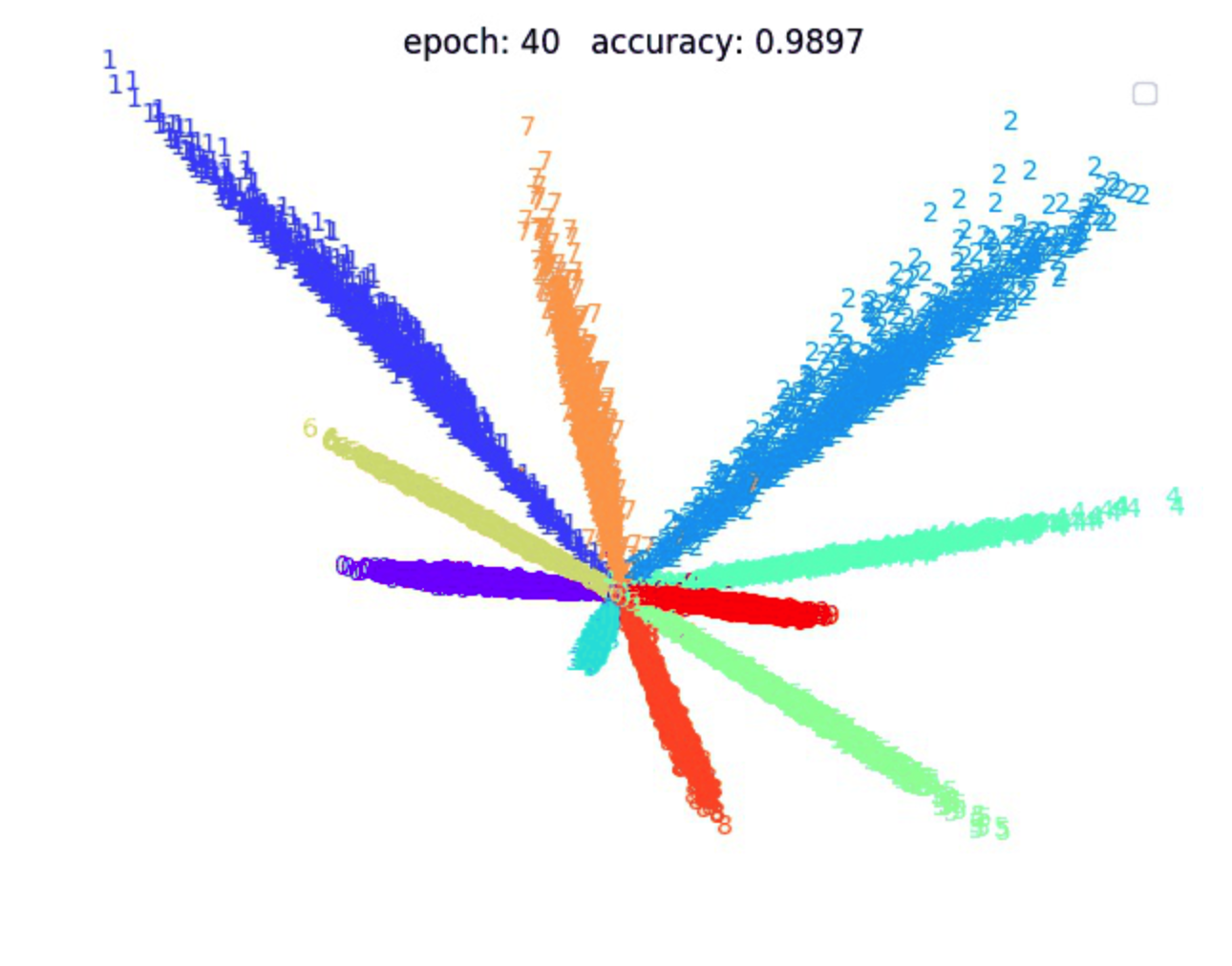
讲到 feature map 哦,就不得不提一下人脸识别领域里经常提到的 embedding. 一般来说,它其实就是 feature map 被最后一层全连接层所提取到特征向量。早在2006年,深度学习鼻祖 hinton 就在《SCIENCE》上发表了一篇论文,首次利用自编码网络对 mnist 手写数字提取出了特征向量(一个2维或3维的向量)。值得一提的是,也是这篇论文揭开了深度学习兴起的序幕。

下面就是上面这张图片里的数字在 CNN 空间里映射后得到的特征向量在2维空间里的样子(假如你对这块感兴趣可以看我之前的工作):
前面我们提到:CNN 网络在对图像自底向上提取特征时,得到的 feature map 一般都是在空间尺寸上越来越小,而在通道尺寸上变得越来越深。 那么,为什么要这么做?
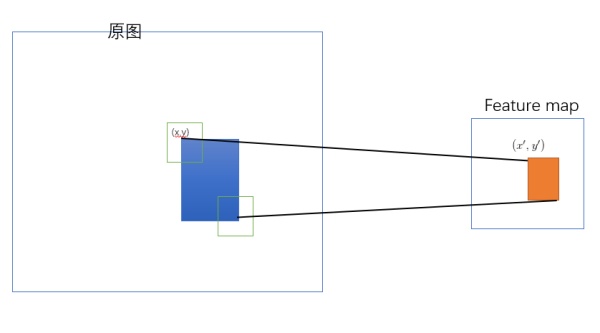
其实,这就与 ROI (感兴趣区域)映射到 Feature Map 有关。在上面这幅图里:原图里的一块 ROI 在 CNN 网络空间里映射后,在 feature map 上空间尺寸会变得更小,甚至是一个点, 但是这个点的通道信息会很丰富,这些通道信息是 ROI 区域里的图片信息在 CNN 网络里映射得到的特征表示。由于图像中各个相邻像素在空间上的联系很紧密,这在空间上造成具有很大的冗余性。因此,我们往往会通过在空间上降维,而在通道上升维的方式来消除这种冗余性,尽量以最小的维度来获得它最本质的特征。

原图左上角红色 ROI 经 CNN 映射后在 feature map 空间上只得到了一个点,但是这个点有85个通道。那么,ROI的维度由原来的 [32, 32, 3] 变成了现在的 85 维,这难道又不是降维打击么?👊
按照我的理解,这其实就是 CNN 网络对 ROI 进行特征提取后得到的一个 85 维的特征向量。这个特征向量前4个维度代表的是候选框信息,中间这个维度代表是判断有无物体的概率,后面80个维度代表的是对 80 个类别的分类概率信息。
5. 如何检测
5.1 多尺度检测
YOLOv3 对输入图片进行了粗、中和细网格划分,以便分别实现对大、中和小物体的预测。假如输入图片的尺寸为 416X416, 那么得到粗、中和细网格尺寸分别为 13X13、26X26 和 52X52。这样一算,那就是在长宽尺寸上分别缩放了 32、16 和 8 倍。

5.2 decode 处理
YOLOv3 网络的三个分支输出会被送入 decode 函数中对 Feature Map 的通道信息进行解码。 在下面这幅图里:黑色虚线框代表先验框(anchor),蓝色框表示的是预测框.
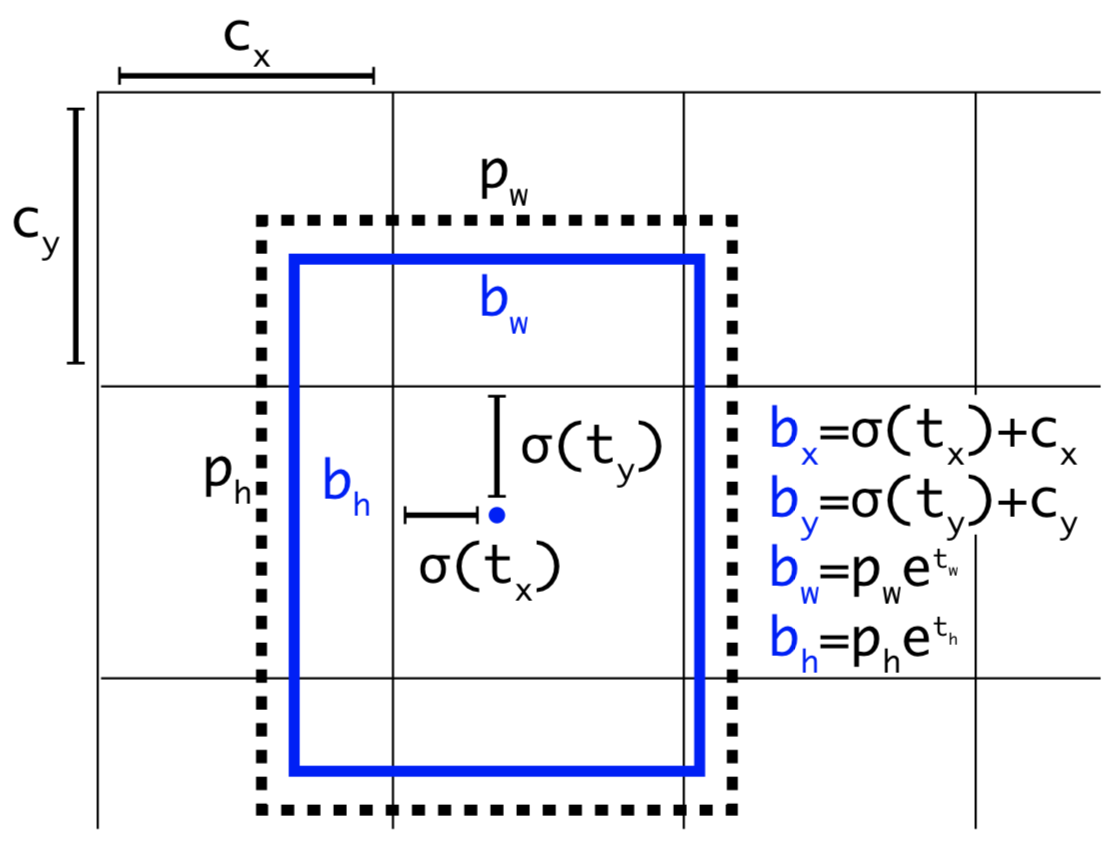
- $b_{h}$ 和 $b_{w}$ 分别表示预测框的长宽,$P_{h}$ 和 $P_{w}$ 分别表示先验框的长和宽。
- $t_{x}$ 和 $t_{y}$ 表示的是物体中心距离网格左上角位置的偏移量,$C_{x}$ 和 $C_{y}$ 则代表网格左上角的坐标。
def decode(conv_output, i=0): |
5.3 NMS 处理
非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,说白了就是去除掉那些重叠率较高并且 score 评分较低的边界框。 NMS 的算法非常简单,迭代流程如下:
- 流程1: 判断边界框的数目是否大于0,如果不是则结束迭代;
- 流程2: 按照 socre 排序选出评分最大的边界框 A 并取出;
- 流程3: 计算这个边界框 A 与剩下所有边界框的 iou 并剔除那些 iou 值高于阈值的边界框,重复上述步骤;
# 流程1: 判断边界框的数目是否大于0 |
最后所有取出来的边界框 A 就是我们想要的。不妨举个简单的例子:假如5个边界框及评分为: A: 0.9,B: 0.08,C: 0.8, D: 0.6,E: 0.5,设定的评分阈值为 0.3,计算步骤如下。
- 步骤1: 边界框的个数为5,满足迭代条件;
- 步骤2: 按照 socre 排序选出评分最大的边界框 A 并取出;
- 步骤3: 计算边界框 A 与其他 4 个边界框的 iou,假设得到的 iou 值为:B: 0.1,C: 0.7, D: 0.02, E: 0.09, 剔除边界框 C;
- 步骤4: 现在只剩下边界框 B、D、E,满足迭代条件;
- 步骤5: 按照 socre 排序选出评分最大的边界框 D 并取出;
- 步骤6: 计算边界框 D 与其他 2 个边界框的 iou,假设得到的 iou 值为:B: 0.06,E: 0.8,剔除边界框 E;
- 步骤7: 现在只剩下边界框 B,满足迭代条件;
- 步骤8: 按照 socre 排序选出评分最大的边界框 B 并取出;
- 步骤9: 此时边界框的个数为零,结束迭代。
最后我们得到了边界框 A、B、D,但其中边界框 B 的评分非常低,这表明该边界框是没有物体的,因此应当抛弃掉。在代码中:
# # (5) discard some boxes with low scores |
在 YOLO 算法中,NMS 的处理有两种情况:一种是所有的预测框一起做 NMS 处理,另一种情况是分别对每个类别的预测框做 NMS 处理。后者会出现一个预测框既属于类别 A 又属于类别 B 的现象,这比较适合于一个小单元格中同时存在多个物体的情况。
6. anchor 响应机制
6.1 K-means 聚类
首先需要抛出一个问题:先验框 anchor 是怎么来的?对于这点,作者在 YOLOv2 论文里给出了很好的解释:
we run k-means clustering on the training set bounding boxes to automatically find good priors.
其实就是使用 k-means 算法对训练集上的 boudnding box 尺度做聚类。此外,考虑到训练集上的图片尺寸不一,因此对此过程进行归一化处理。
k-means 聚类算法有个坑爹的地方在于,类别的个数需要人为事先指定。这就带来一个问题,先验框 anchor 的数目等于多少最合适?一般来说,anchor 的类别越多,那么 YOLO 算法就越能在不同尺度下与真实框进行回归,但是这样就会导致模型的复杂度更高,网络的参数量更庞大。

We choose k = 5 as a good tradeoff between model complexity and high recall. If we use 9 centroids we see a much higher average IOU. This indicates that using k-means to generate our bounding box starts the model off with a better representation and makes the task easier to learn.
在上面这幅图里,作者发现 k = 5 时就能较好地实现高召回率与模型复杂度之间的平衡。由于在 YOLOv3 算法里一共有3种尺度预测,因此只能是3的倍数,所以最终选择了 9 个先验框。这里还有个问题需要解决,k-means 度量距离的选取很关键。距离度量如果使用标准的欧氏距离,大框框就会比小框产生更多的错误。在目标检测领域,我们度量两个边界框之间的相似度往往以 IOU 大小作为标准。因此,这里的度量距离也和 IOU 有关。需要特别注意的是,这里的IOU计算只用到了 boudnding box 的长和宽。在我的代码里,是认为两个先验框的左上角位置是相重合的。(其实在这里偏移至哪都无所谓,因为聚类的时候是不考虑 anchor 框的位置信息的。)
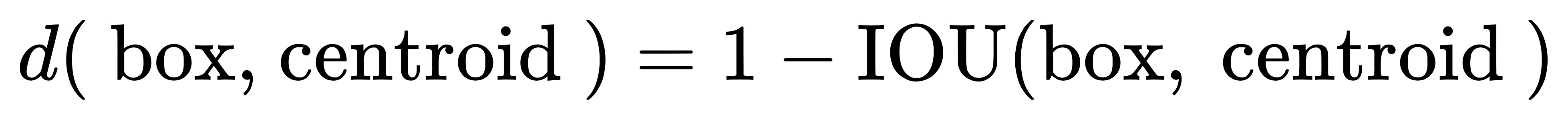
如果两个边界框之间的IOU值越大,那么它们之间的距离就会越小。
def kmeans(boxes, k, dist=np.median,seed=1): |
6.2 正负样本分配
- 如果 Anchor 与 Ground-truth Bounding Boxes 的 IoU > 0.3,标定为正样本;
- 在第 1 种规则下基本能够产生足够多的样本,但是如果它们的 iou 不大于 0.3,那么只能把 iou 最大的那个 Anchor 标记为正样本,这样便能保证每个 Ground-truth 框都至少匹配一个先验框。
按照上述原则,一个 ground-truth 框会同时与多个先验框进行匹配。记得之前有人问过我,为什么不能只用 iou 最大的 anchor 去负责预测该物体?其实我想回答的是,如果按照这种原则去分配正负样本,那么势必会导致正负样本的数量极其不均衡(正样本特别少,负样本特别多),这将使得模型在预测时会出现大量漏检的情况。实际上很多目标检测网络都会避免这种情况,并且尽量保持正负样本的数目相平衡。例如,SSD 网络就使用了 hard negative mining 的方法对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差较大的 top-k 作为训练的负样本,以保证正负样本的比例接近1:3。
for i in range(3): # 针对 3 种网格尺寸 |
按照上面两种规则标记出正样本后,剩下的都是负样本了。这些负样本是不会参与到边界框损失和分类损失的计算中去,而只会参与到置信度损失的计算(因为你需要告诉神经网络什么是负样本)。在这里,你不必纠结 Anchor 是否能够准确地框到物体。你只要关心 Anchor 能不能框到物体,如果框到很多了(比如iou>0.3),那么它就是个正样本了,否则就不是了。 后面的损失函数会进一步告诉神经网络怎么去做精确的尺寸和位置回归,并给出一个置信度评分。最后,那些评分比较低和重叠度较高的预测框就会被 NMS 算法给过滤掉。
7. 损失函数
在 YOLOv3 中,作者将目标检测任务看作目标区域预测和类别预测的回归问题, 因此它的损失函数也有些与众不同。对于损失函数, Redmon J 在论文中并 没有进行详细的讲解。但通过对 darknet 源代码的解读,可以总结得到 YOLOv3 的损失函数如下:
- 置信度损失,判断预测框有无物体;
- 框回归损失,仅当预测框内包含物体时计算;
- 分类损失,判断预测框内的物体属于哪个类别
7.1 置信度损失
YOLOv3 直接优化置信度损失是为了让模型去学习分辨图片的背景和前景区域,这类似于在 Faster rcnn 里 RPN 功能。
iou = bbox_iou(pred_xywh[:, :, :, :, np.newaxis, :], bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :]) |
判定的规则很简单:如果一个预测框与所有真实框的 iou 都小于某个阈值,那么就判定它是背景,否则为前景(包含物体)。
7.2 分类损失
这里分类损失采用的是二分类的交叉熵,即把所有类别的分类问题归结为是否属于这个类别,这样就把多分类看做是二分类问题。这样做的好处在于排除了类别的互斥性,特别是解决了因多个类别物体的重叠而出现漏检的问题。
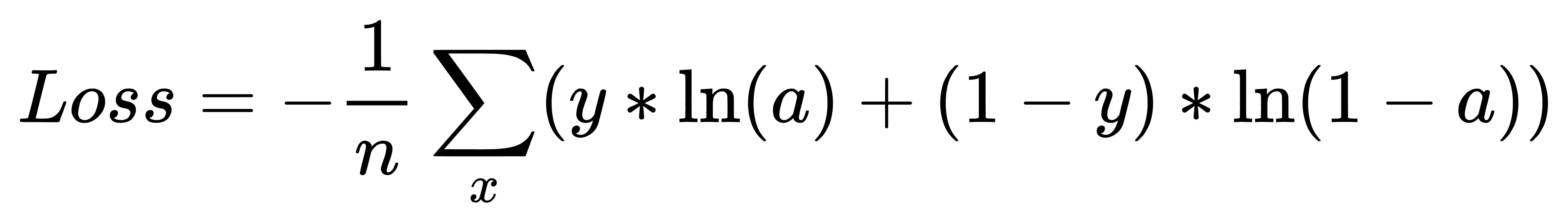
respond_bbox = label[:, :, :, :, 4:5] |
7.3 框回归损失
respond_bbox = label[:, :, :, :, 4:5] # 置信度,判断网格内有无物体 |
- 边界框的尺寸越小,bbox_loss_scale 的值就越大。实际上,我们知道 YOLOv1 里作者在 loss 里对宽高都做了开根号处理,这是为了弱化边界框尺寸对损失值的影响;
- respond_bbox 的意思是如果网格单元中包含物体,那么就会计算边界框损失;
- 两个边界框之间的 GIoU 值越大,giou 的损失值就会越小, 因此网络会朝着预测框与真实框重叠度较高的方向去优化。
受 g-darknet 所启示,将原始 iou loss 替换成了 giou loss ,检测精度提高了大约 1 个百分点。 GIoU 的好处在于,改进了预测框与先验框的距离度量方式。
GIoU 的背景介绍
这篇论文 出自于 CVPR 2019,这篇论文提出了一种优化边界框的新方式 —— GIoU (Generalized IoU,广义 IoU )。边界框一般由左上角和右下角坐标所表示,即 (x1,y1,x2,y2)。那么,你发现这其实也是一个向量。向量的距离一般可以 L1 范数或者 L2 范数来度量。但是在L1及L2范数取到相同的值时,实际上检测效果却是差异巨大的,直接表现就是预测和真实检测框的IoU值变化较大,这说明L1和L2范数不能很好的反映检测效果。
L1 范数:向量元素的绝对值之和;
L2 范数:即欧几里德范数,常用于计算向量的长度;
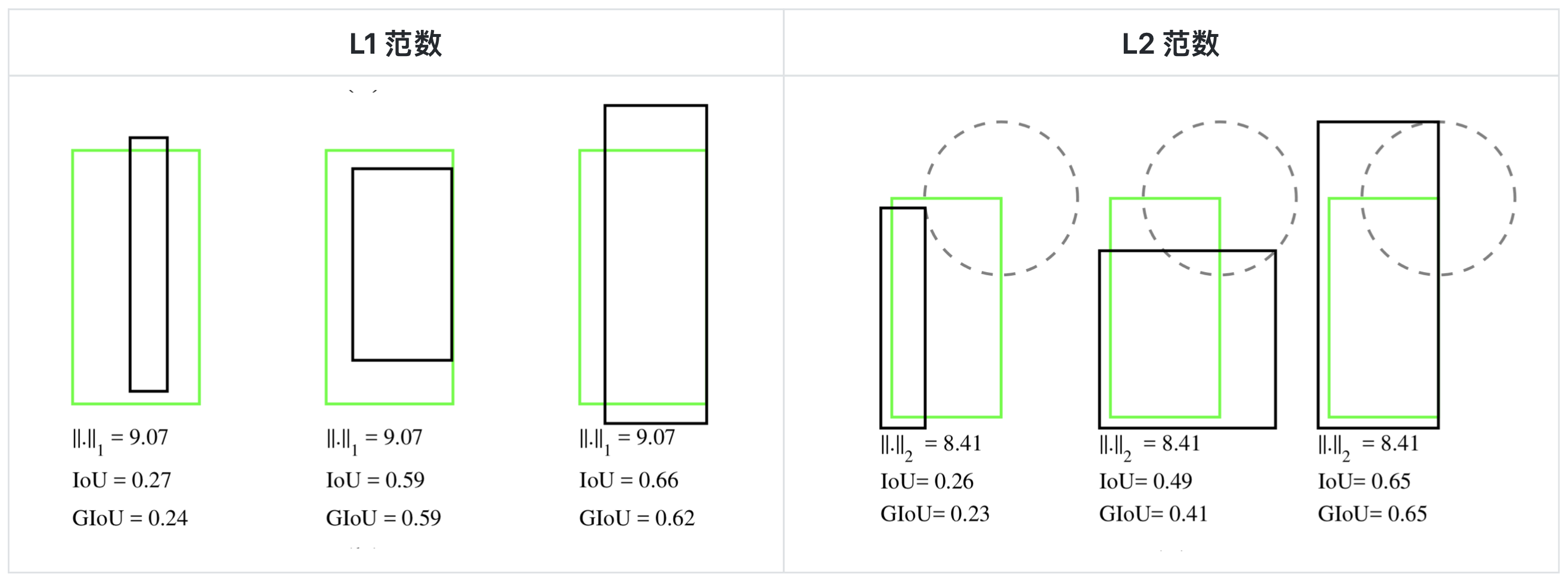
当 L1 或 L2 范数都相同的时候,发现 IoU 和 GIoU 的值差别都很大,这表明使用 L 范数来度量边界框的距离是不合适的。在这种情况下,学术界普遍使用 IoU 来衡量两个边界框之间的相似性。作者发现使用 IoU 会有两个缺点,导致其不太适合做损失函数:
- 预测框和真实框之间没有重合时,IoU 值为 0, 导致优化损失函数时梯度也为 0,意味着无法优化。例如,场景 A 和场景 B 的 IoU 值都为 0,但是显然场景 B 的预测效果较 A 更佳,因为两个边界框的距离更近( L 范数更小)。

尽管场景 A 和场景 B 的 IoU 值都为 0,但是场景 B 的预测效果较 A 更佳,这是因为两个边界框的距离更近。
- 即使预测框和真实框之间相重合且具有相同的 IoU 值时,检测的效果也具有较大差异,如下图所示。
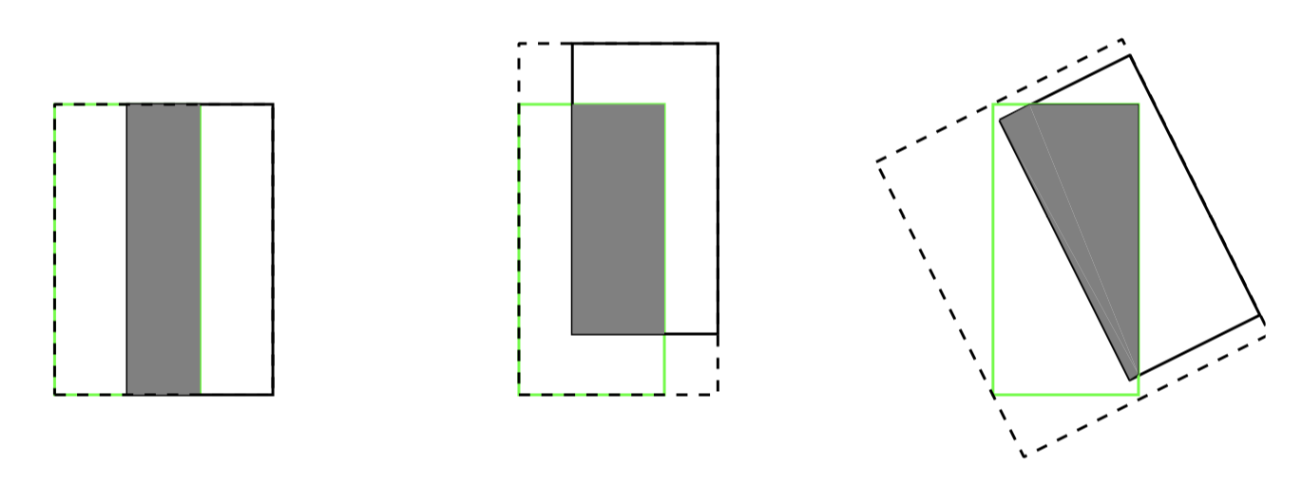
上面三幅图的 IoU = 0.33, 但是 GIoU 值分别是 0.33, 0.24 和 -0.1, 这表明如果两个边界框重叠和对齐得越好,那么得到的 GIoU 值就会越高。
GIoU 的计算公式

the smallest enclosing convex object C 指的是最小闭合凸面 C,例如在上述场景 A 和 B 中,C 的形状分别为:

图中绿色包含的区域就是最小闭合凸面 C,the smallest enclosing convex object。
def bbox_giou(boxes1, boxes2): |
8. 模型训练
8.1 权重初始化
训练神经网络尤其是深度神经网络所面临的一个问题是,梯度消失或梯度爆炸,也就是说 当你训练深度网络时,导数或坡度有时会变得非常大,或非常小甚至以指数方式变小,这个时候我们看到的损失就会变成了 NaN。假设你正在训练下面这样一个极深的神经网络,为了简单起见,这里激活函数 g(z) = z 并且忽略偏置参数。

这里我们首先假定 g(z)=z, b[l]=0,所以对目标输出有:
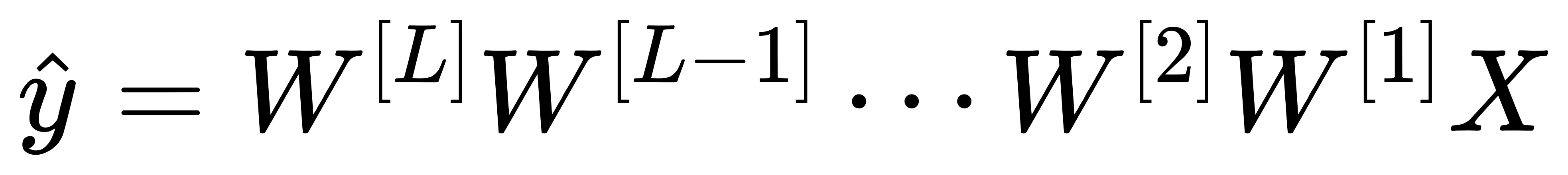
其实这里直观的理解是:如果权重 W 只比 1 略大一点,或者说只比单位矩阵大一点,深度神经网络的输出将会以爆炸式增长,而如果 W 比 1 略小一点,可能是 0.9, 0.9,每层网络的输出值将会以指数级递减。因此合适的初始化权重值就显得尤为重要! 下面就写个简单的代码给大家演示一下。
import numpy as np |
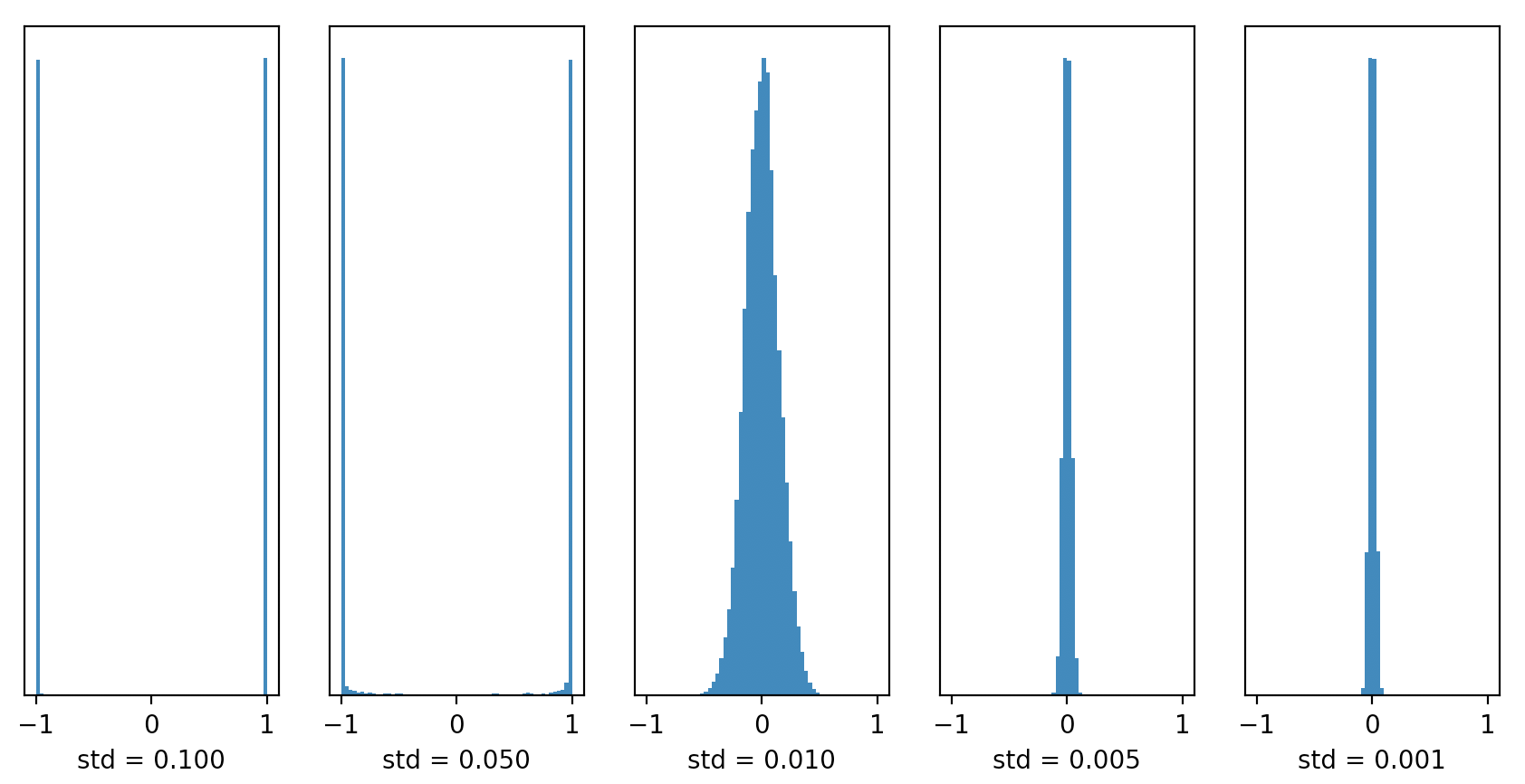
我们可以看到当标准差较大( std = 0.1 和 0.05 )时,几乎所有的输出值集中在 -1 或1 附近,这表明此时的神经网络发生了梯度爆炸;当标准差较小( std = 0.005 和 0.001)时,我们看到输出值迅速向 0 靠拢,这表明此时的神经网络发生了梯度消失。其实笔者也曾在 YOLOv3 网络里做过实验,初始化权重的标准差如果太大或太小,都容易出现 NaN 。
8.2 学习率的设置
学习率是最影响性能的超参数之一,如果我们只能调整一个超参数,那么最好的选择就是它。 其实在我们的大多数的炼丹过程中,遇到 loss 变成 NaN 的情况大多数是由于学习率选择不当引起的。
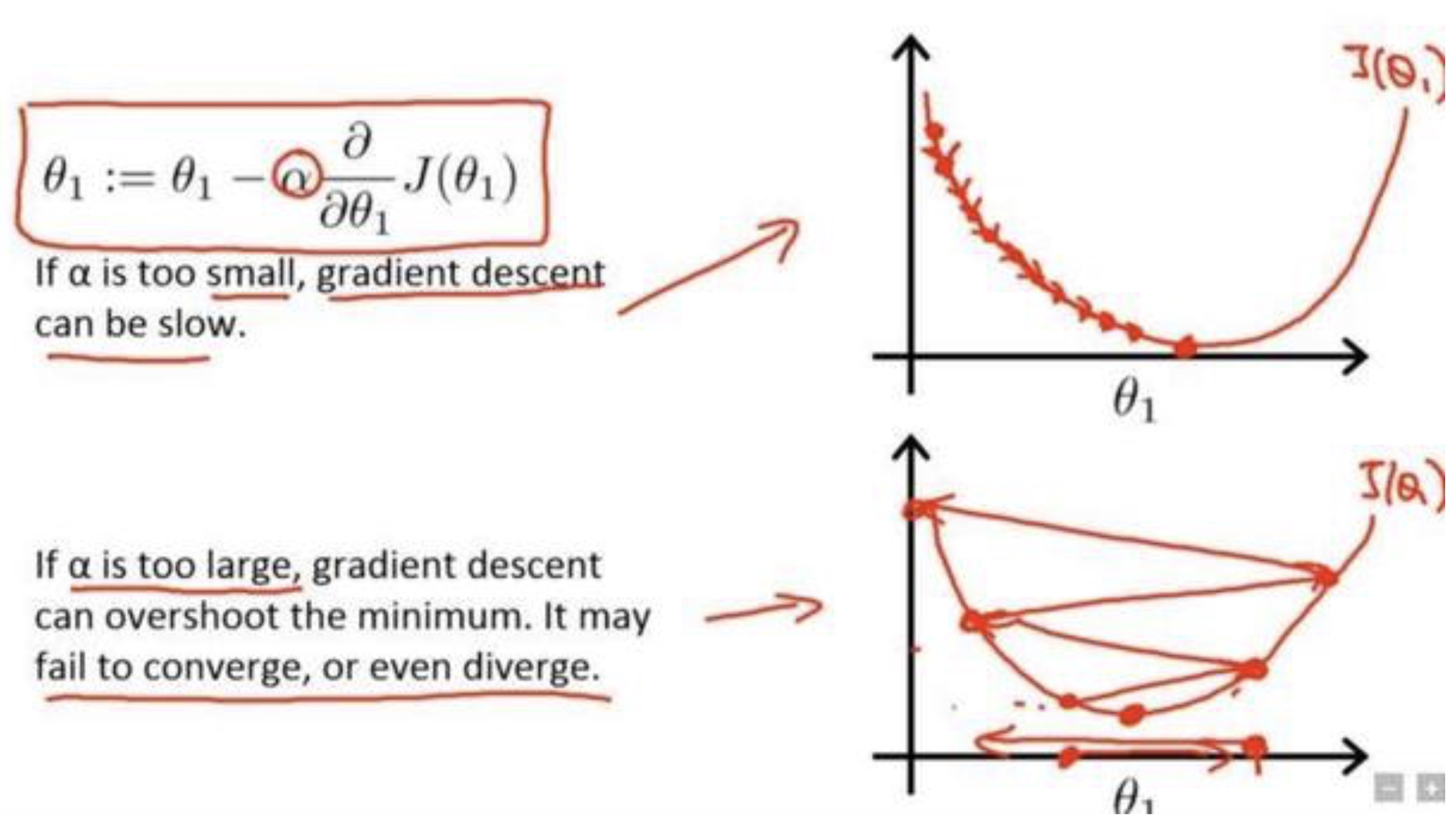
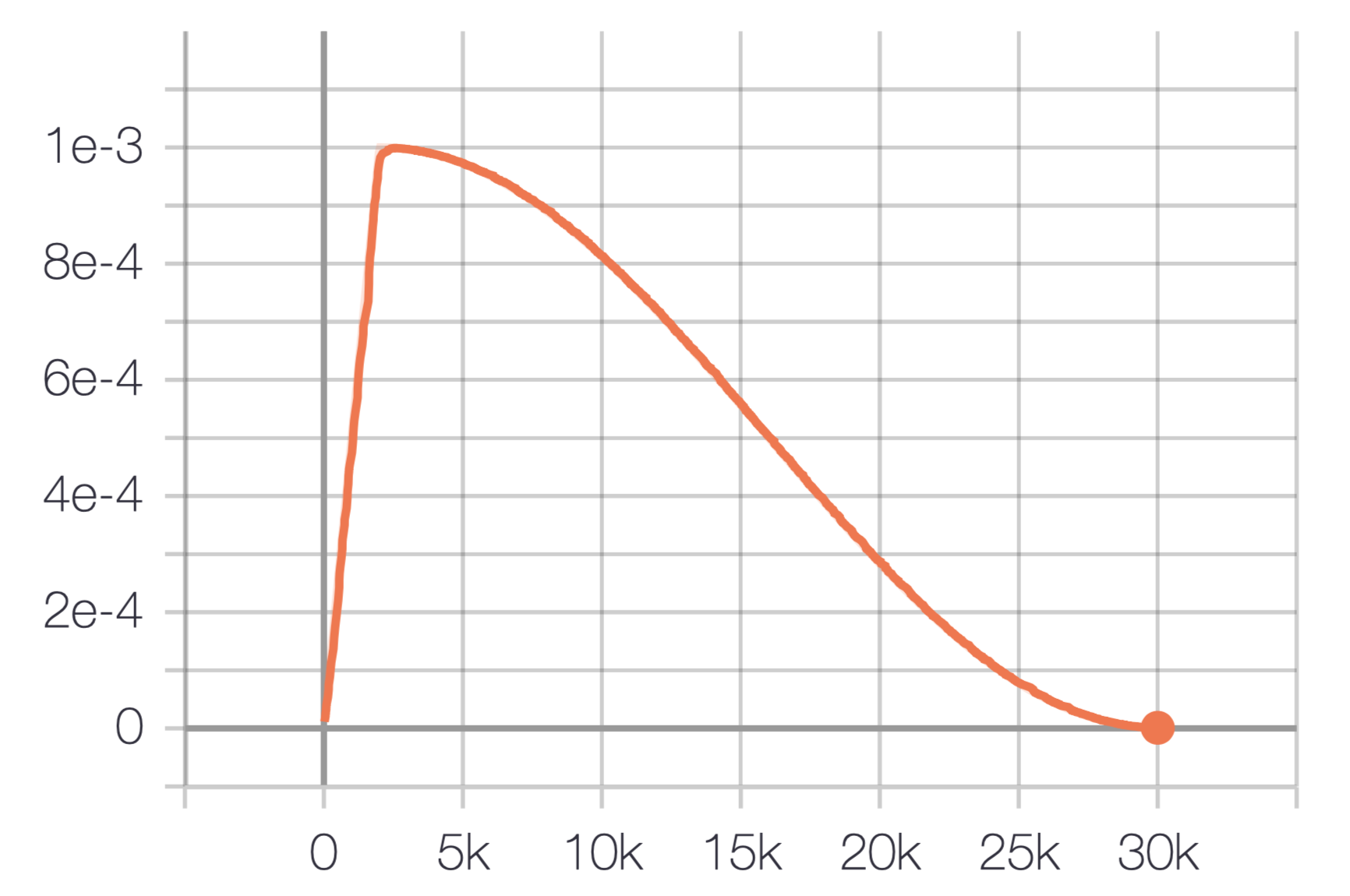
有句话讲得好啊,步子大了容易扯到蛋。由于神经网络在刚开始训练的时候是非常不稳定的,因此刚开始的学习率应当设置得很低很低,这样可以保证网络能够具有良好的收敛性。但是较低的学习率会使得训练过程变得非常缓慢,因此这里会采用以较低学习率逐渐增大至较高学习率的方式实现网络训练的“热身”阶段,称为 warmup stage。但是如果我们使得网络训练的 loss 最小,那么一直使用较高学习率是不合适的,因为它会使得权重的梯度一直来回震荡,很难使训练的损失值达到全局最低谷。因此最后采用了这篇论文里[8]的 cosine 的衰减方式,这个阶段可以称为 consine decay stage。
if global_steps < warmup_steps: |
8.3 加载预训练模型
目前针对目标检测的主流做法是基于 Imagenet 数据集预训练的模型来提取特征,然后在 COCO 数据集进行目标检测fine-tunning训练(比如 yolo 算法),也就是大家常说的迁移学习。其实迁移学习是建立在数据集分布相似的基础上的,像 yymnist 这种与 COCO 数据集分布完全不同的情况,就没有必要加载 COCO 预训练模型的必要了吧。
在 tensorflow-yolov3 版本里,由于 README 里训练的是 VOC 数据集,因此推荐加载预训练模型。由于在 YOLOv3 网络的三个分支里的最后卷积层与训练的类别数目有关,因此除掉这三层的网络权重以外,其余所有的网络权重都加载进来了。
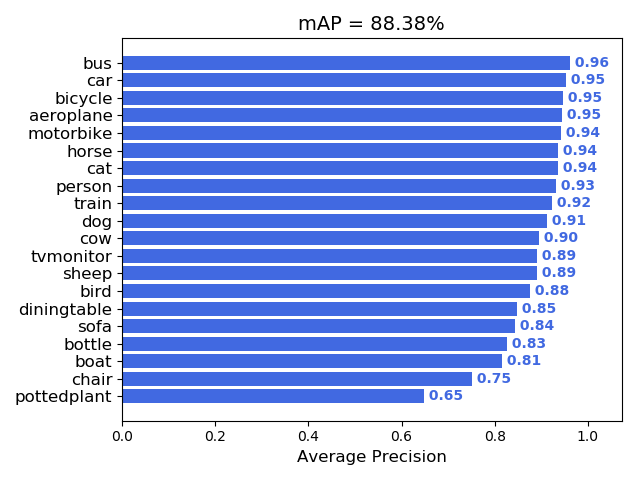
下面是 tensorflow-yolov3 在 PASCAL VOC 2012 上比赛刷的成绩,最后进了榜单的前十名。
参考文献
- [1] Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation, CVPR 2014
- [2] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, CVPR 2016
- [3] Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi. You Only Look Once: Unified, Real-Time Object Detection, CVPR 2016
- [4] Joseph Redmon, Ali Farhadi. YOLO9000: Better, Faster, Stronger, CVPR 2017
- [5] Joseph Redmon, Ali Farhadi. YOLOv3: An Incremental Improvement
- [6] Conv2DTranspose 层,Keras 中文文档.
- [7] Rezatofighi, Hamid. Generalized Intersection over Union, A Metric and A Loss for Bounding Box Regression, CVPR 2018
- [8] Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li. Bag of Tricks for Image Classification with Convolutional Neural Networks