医学图片分割网络 —— Unet
Unet 是 Kaggle 语义分割挑战赛上的常客。因为它简单,高效,易懂,容易定制,最主要的是它可以从相对较小的数据集中学习。在医学图像处理领域,各路高手更是拿着 Unet 各种魔改。
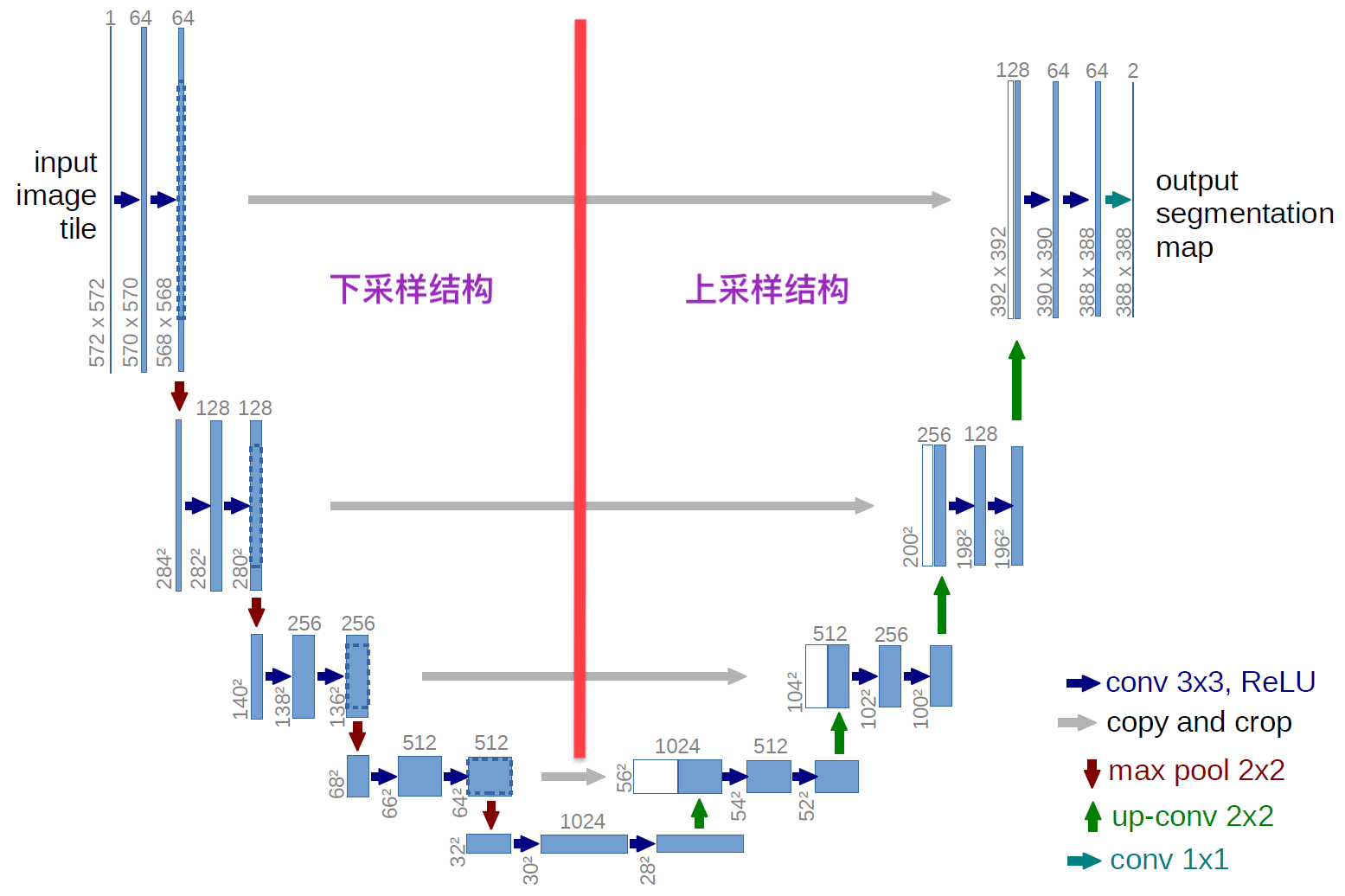
1. 网络结构
U-Net 与 FCN 非常的相似(比如都没有使用全连接层),U-Net 比 FCN 稍晚提出来,但都发表在 2015 年,和 FCN 相比,U-Net 的第一个特点是完全对称,也就是左边和右边是很类似的。当我第一次看到该网络的拓扑结构时,顿时惊为天人,卧槽,简直是一个大写的 U。
其次,Unet 与 FCN 第二个不同点就是 skip-connections(跳跃连接)的操作不一样:FCN 采用的是 tf.add,而 Unet 则使用的 tf.concat 操作,它们之间的区别在于前者在 pixel-to-pixel 上直接相加,而后者是相叠加而改变了通道数目。Unet 的网络结构主要包括三点:
- 下采样路径, 论文里称为 The contracting path;
- Bottleneck 结构;
- 上采样路径,论文里称为 The expanding path;
2. 下采样路径
下采样路径一共由4个模块组成,每个模块的结构为:
- 3x3 的卷积操作 + relu 激活函数;
- 3x3 的卷积操作 + relu 激活函数;
- 2x2 的 Pooling 操作。
It consists of the repeated application of two 3x3 convolutions (unpadded convolutions), each followed by a rectified linear unit (ReLU) and a 2x2 max pooling operation with stride 2 for downsampling. At each downsampling step we double the number of feature channels.
但是值得一提的是每次在 Pooling 结构后,feature map 的通道数目就会加倍,最终 feature map 的空间尺寸越来越小,而通道数目越来越多。这样做的目的是为了捕获输入图像的上下文信息,以便能够进行分割。随后,这些粗略的上下文信息随后将通过跳跃连接传输到上采样路径。
3. Bottleneck 结构
瓶颈结构,顾名思义,就是在下采样和上采样之间的结构。它由两个卷积层组成,并且后面接有 dropout。在代码里是这样实现的:
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same')(pool4) |
4. 上采样路径
跟下采样结构一样,上采样结构也是由 4 个模块组成,这样才能对称,每个模块都结构为:
- 上采样层;
- 3x3 卷积操作 + relu 激活函数;
不过这里面多了一些骚操作,在对称的地方与来自下采样路径的跳跃连接进行了 Concate 操作,从而融合网络的浅层特征。
5. 个人思考
从 Unet 的主体结构设计来看,其实是借鉴了 Hinton 祖师爷的自编码网络。仔细看 Unet 会发现:它的下采样结构其实是一个编码过程,所谓的编码就是尽可能地压缩图像的空间信息,而保留最本质的特征;上采样结构则是一个解码过程,尽可能地还原到原来的图像。在 FCN 的 skip-connection 提出后,这几乎成了语义分割和目标检测领域的标配,因此 Unet 网络避免不了得用它。所以 Unet 更像是 AutoEncoder 与 FCN 的结合版。
参考文献
- [1] Olaf Ronneberger, Philipp Fischer, Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation, accepted at MICCAI 2015