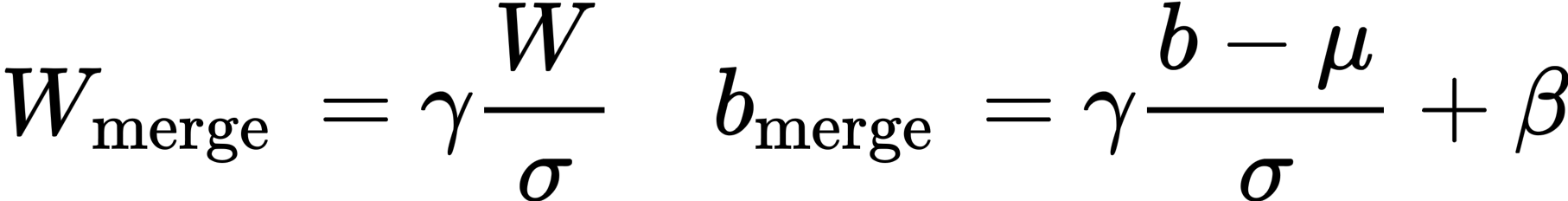理解英伟达 TensorRT 的 INT8 加速原理
目前的神经网络推理大部分是利用 32bit float 类型的数据进行计算的,bit 位数的多少直接限制了数据类型能够表达的数据范围,比如 float 32 的数据是由 1bit 表示符号,8bit 表示整数部,23 位表示分数部组成。但是这种运算比较耗时和消耗计算资源,因此诞生了 int8 量化算法。

int8 量化是将数据保存为 int8 格式,这样一样计算时间和占用内存大大减小。目前量化有两种方式:一种是通过训练量化 finetune 原来的模型,另一种是直接对模型和计算进行量化。后者的代表便是英伟达的方案了,目前 PPT 已经公开,但是代码并没有开源。
1. 量化卷积核权重
量化的目的是为了把原来的 float32 位的卷积操作,转换为 int8 的卷积操作,这样计算就变为原来的 1/4,但是访存并没有变少哈,因为我们是在 kernel 里面才把 float32 变为 int8 进行计算的。
比如说 float32 位的变量 a=6.238561919405008,可以通过 scale=23.242536 映射到 int8 空间上到整数 a*scale=145。
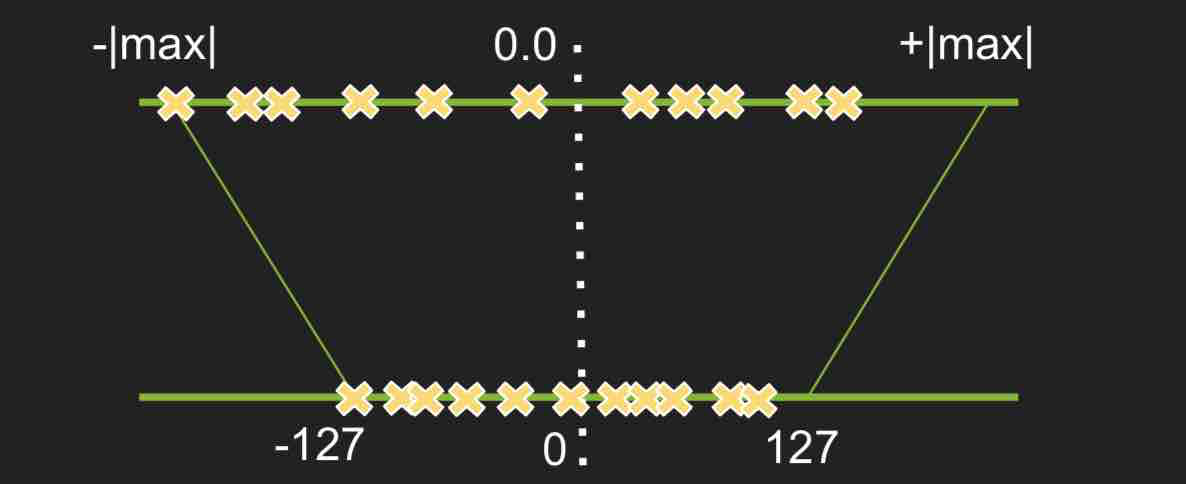
如上所示,这个 scale 是根据最大的权重绝对值 thresh 决定的,然后计算 127 与它的比值,便得到了 scale 值。
def quantize_weight(self): |
由于卷积运算是卷积核(weights)和数据流(blob)之间乘加操作,因此光对卷积核量化是不够的,还需要对数据流进行量化!
2. 量化输入数据流
我们发现,量化的过程与数据的分布有关。如下图所示:当数据的直方图分布比较均匀时,高精度向低精度进行映射就会将刻度利用比较充分;如果分布不均匀,就会浪费很大空间。通俗地来讲,就会出现很多数字挤在一个刻度里:比如 scale=23.456 时,6.1817 和 6.1823 都表示成了 145。
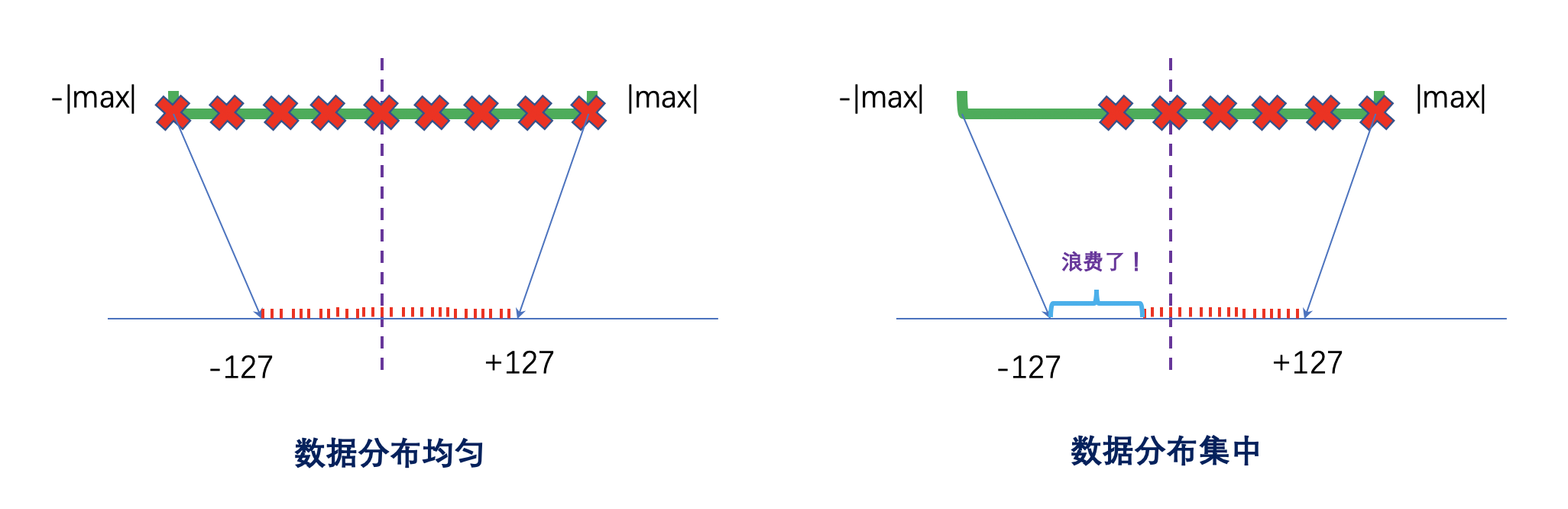
关于上面这种直接将量化阈值设置为 |max| 的方法,它的显著特点是低精度的 int8 空间没有充分利用,因此称为不饱和量化(no saturation quantization)。针对这种情况,我们可以选择一个合适的量化阈值(threshold),舍弃那些超出范围的数进行量化,这种量化方式充分利用了低精度空间,因此称为饱和量化(saturation quantization)。
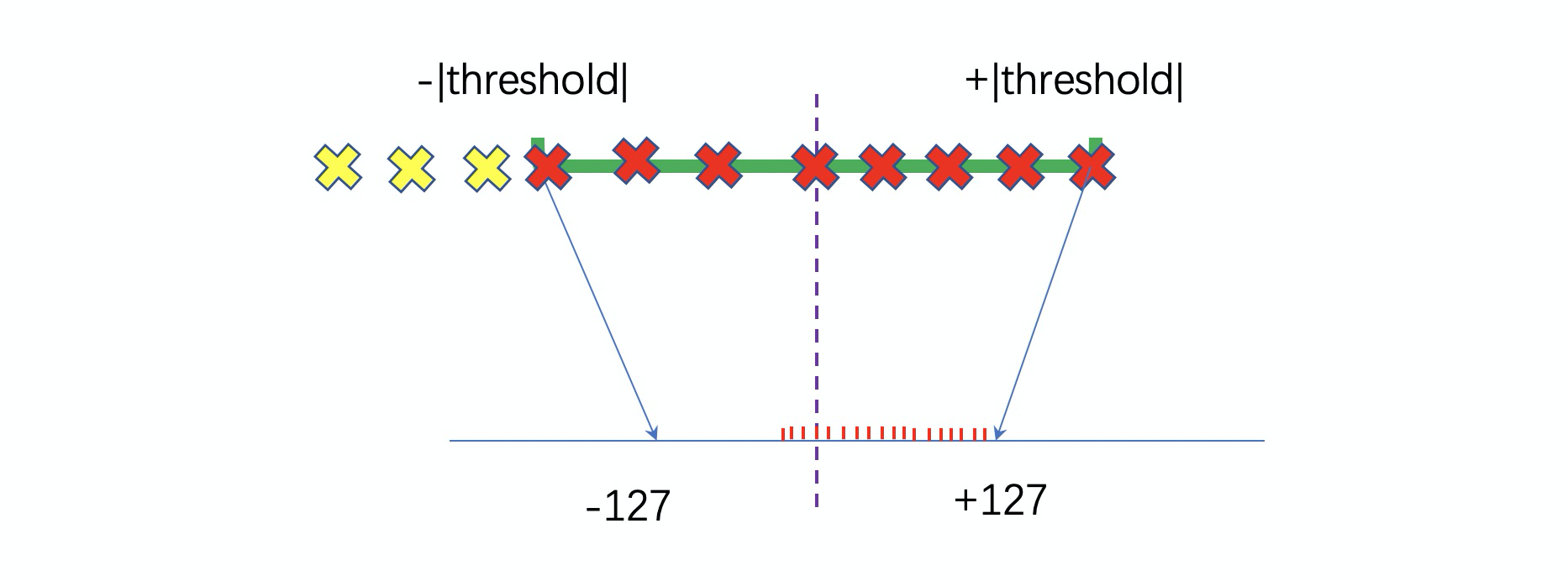
图中黄色部分被舍弃掉了,它们将直接被量化为 -127
通过对比两种量化方式我们可以发现,它们各有优缺点:不饱和量化方式的量化范围大,但是可能会浪费一些低精度空间从而导致量化精度低;饱和量化方式虽然充分利用了低精度空间,但是会舍弃一些量化范围。因此这两种方式其实是一个量化精度和量化范围之间的平衡。那么如何选择合适的量化方式呢,英伟达说了:卷积核权重量化应该使用不饱和量化,数据流量化应该使用饱和量化方式。那么问题来了,对于数据流的饱和量化,怎么在数据流中找到这个最佳阈值(threshold) ?
我们首先应该将经过网络每一层的数据流(Blob)给提取出来,得到它们的直方图分布。为了提取每一层的输入流,我们可以使用 torch.nn.Module.register_forward_pre_hook 函数来操作。它就像一个钩子,可以把我们想要的东西给钩出来,并且不会对数据进行修改。不妨先在 QuantizeLayer 设置一个 hook 函:
def hook(self, modules, input): |
然后模型每次执行 forward 函数时,都会去执行 hook 函数里的内容:把该层的输入流复制给 blob 变量。
跟权重量化的原理类似,数据流量化也需要找到最大绝对值 blob_max。理论上这个值应该是全局的,但是模型的测试图片数量和分布都具有不可穷举性,因此我们往往会选择一些图片进行校准 (calibration),使得blob_max尽量接近理论值。因此我们在上面这个钩子函数里设置了一个动态规划,数据流每次经过该层时都会对该值进行更新。
for name, layer in model.named_modules(): |
在获得这个 blob_max 值之后,我们会在 (0, blob_max) 划分 2048 个刻度(你也可以划分成4096个刻度,只要你喜欢),然后统计每个刻度范围内的数字出现的个数。例如,VGG16 最后一层输入流的直方图分布为:
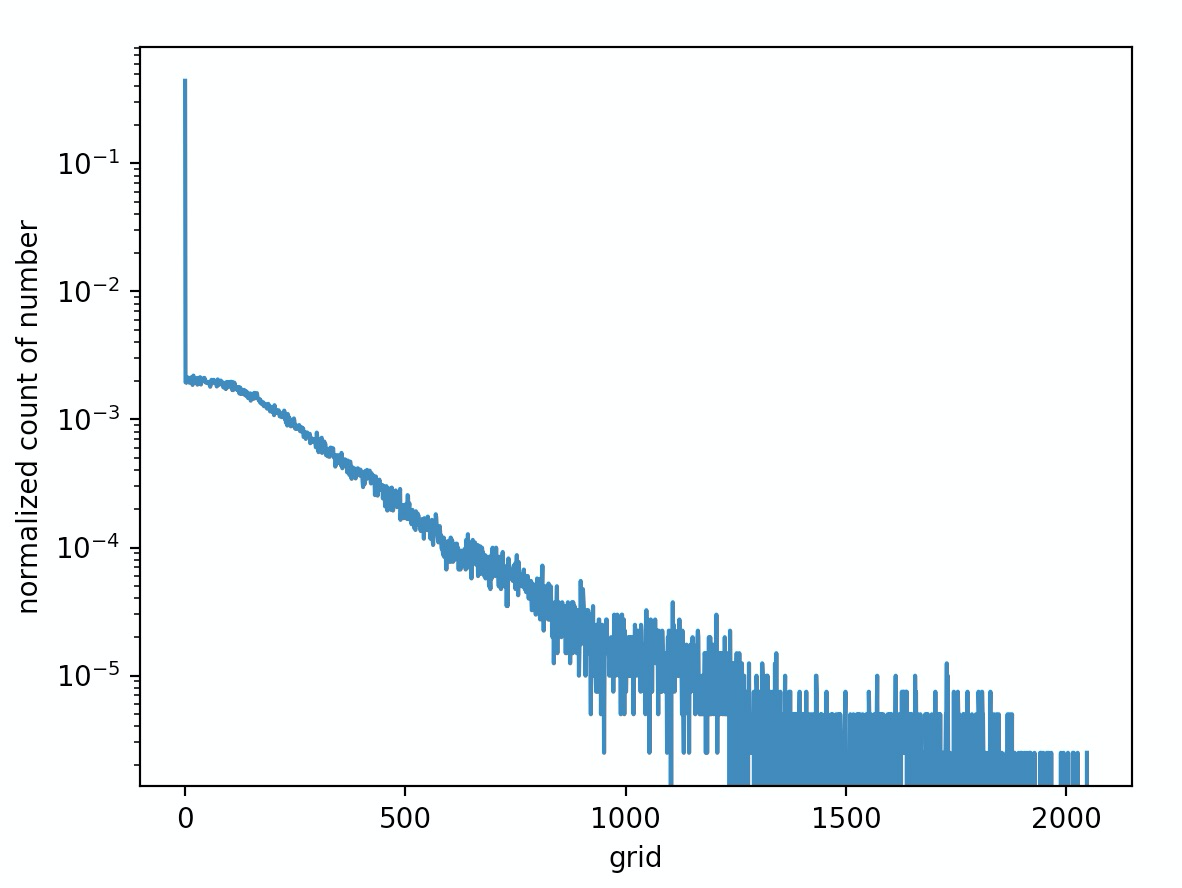
可以看到第
0个刻度的概率特别大,这表明大部分的数字都集中在(-blob_max/2048, blob_max/2048)区间内。
假如我们设定阈值刻度 Threshold=512,因此需要将 512 个刻度合并成 128 个刻度(因为 int8 的正数范围为 0~127,一共 128 个刻度)。假设合并前 (0,512) 的分布为 P, 合并成 (0, 127) 后的分布为 Q。那么我们肯定要计算这两个分布的差异性,并希望它们之间的差异越小越好。
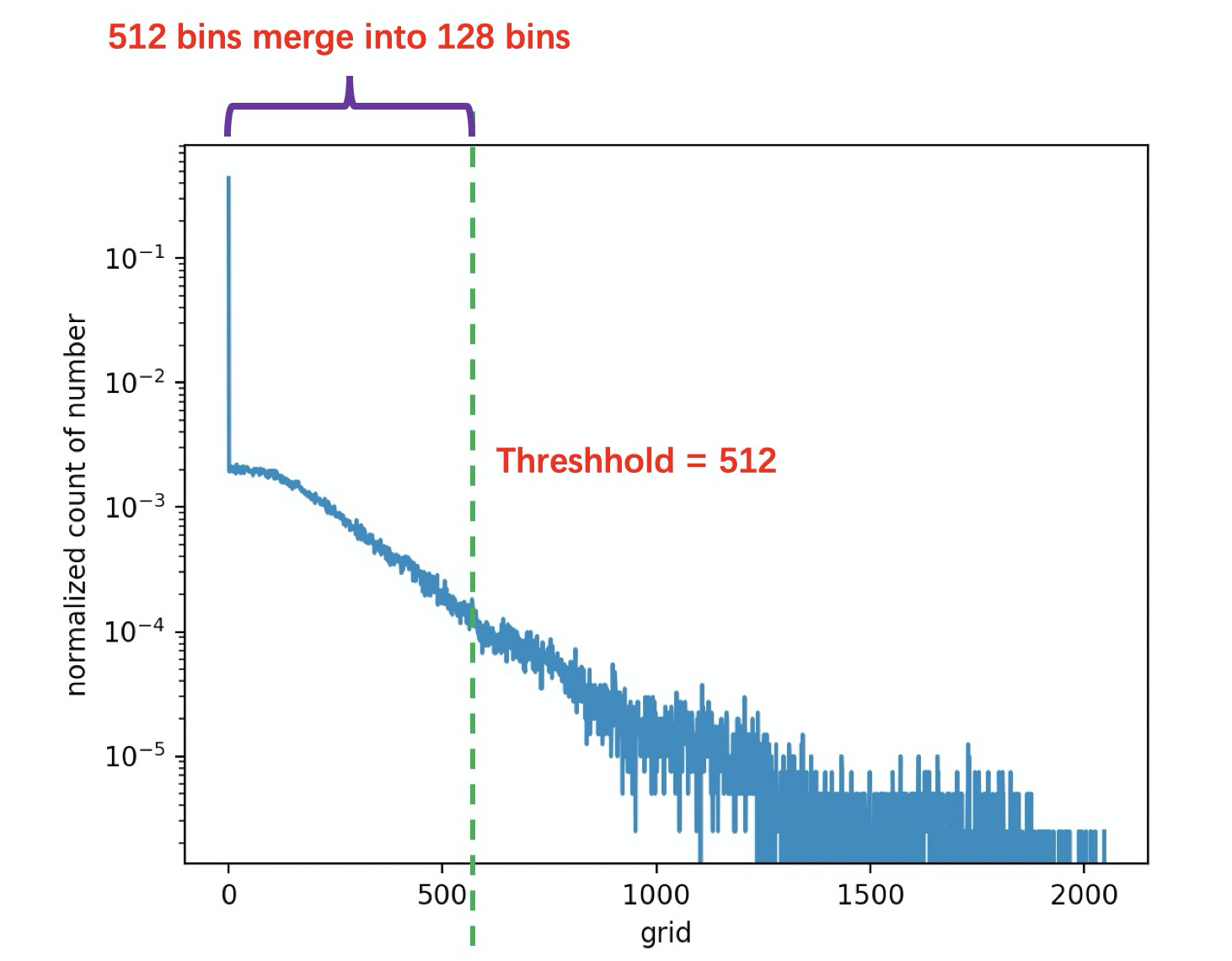
怎么计算两个分布的差异性呢?使用KL 散度就可以!它又称为交叉熵,等于概率分布的信息熵(Shannon entropy)的差值。我们可以使用scipy.stats.entropy(p, q)进行计算,但是它要求两个输入的长度必须相等:len(p) == len(q)。而P和Q的长度分别为512和128,因此我们需要将 Q 拓展回去,其长度也变成512。例如:

| 这里是将阈值刻度 Threshold 假设为 512,但在实际过程中我们需要遍历得到。由于量化刻度为 128,因此我们从 128 起遍历至最后一个刻度,计算出每个对应的 KL 散度值,最后那个最小 KL 散度所对应的刻度即为最佳阈值。 |
def quantize_blob(self): |
一旦获得了最佳阈值刻度后,我们就可以求出每层数据流的 blob_scale 值了,这一步发生在上面的 hook 函数中:
def hook(self, modules, input): |
3. INT8 推理过程
在上面的过程,其实无非就是求卷积核权重和每层 feature map(即数据流)的 scale 值。有了这个 scale 值后,就可以实现 float32 和 int8 数据类型之间的映射。
| 整个 INT8 推理过程可以简述为:输入流 x 在喂入每层卷积之前,需要先乘以 blob_scale 映射为 int8 类型数据,然后得到 int8 类型的卷积结果 x。由于卷积层的偏置 bias 没有被量化,它仍然是 float32 类型,因此我们需要将卷积结果 x 再映射回 float32,然后再与偏置 bias 相加。 |
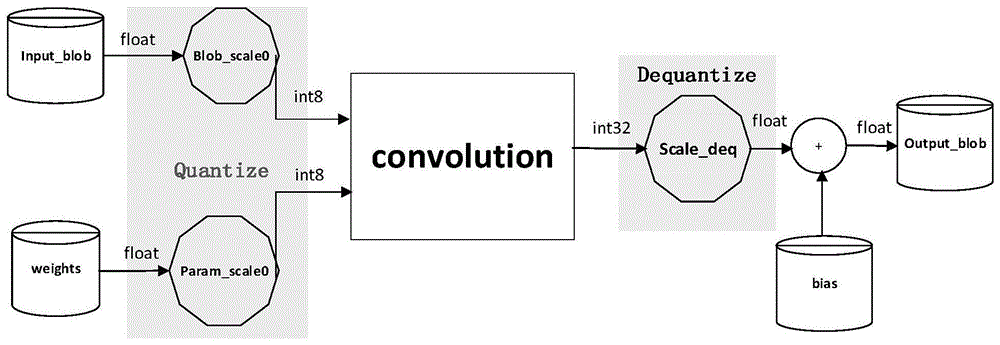
def forward(self, x): |
需要说明的是:在上面的 python 代码中,我们首先将卷积结果 x 减去 bias,然后又分别按照 channel 通道除以 scale 和除以 blob_scale,最后再重新加上 bias 的值。这是因为卷积过程 self.conv1(x) 已经实现了 bias 相加的过程,因此我们要将结果先减去 bias 才能得到真正的卷积结果 x,由于卷积结果 x 的数据类型为 int8,所以要映射回 float32 再与 bias 相加。而实际应用的部署代码中是会将卷积计算和偏置相加的两个过程剥离开来的,这样就不用多此一举地将 bias 相减和相加了。
思考一下,为什么英伟达的 TensorRT 没有对偏置 bias 进行 INT8 量化?我觉得可能是基于以下几点原因:
- 偏置 bias 是加法运算,其性能和开销本身就比卷积核的乘法运算要小很多。
- NVIDIA 的研究人员已经用实验说明了偏置项量化并不太重要,并不能带来很大的性能提升。既然如此,本着奥卡姆剃刀原则,那就不必要牺牲精度来做量化。
| 最后想说说量化适合的应用场景:由于量化是牺牲了部分精度(虽然比较小)来压缩和加速网络,因此不适合精度非常敏感的任务。由于图片的信息冗余是非常大的,比如相邻一块的像素几乎都一模一样,因此用量化处理一些图像任务,比如目标检测、分类等对于精度不是非常敏感的 CV 任务而言是很适合的,但是对于一些回归任务比如深度估计就不太适合了。 |
4. 如何处理 batchnorm 层
对于卷积层之后带batchnorm的网络,因为一般在实际使用阶段,为了优化速度,batchnorm 的参数都会提前融合进卷积层的参数中,所以训练模拟量化的过程也要按照这个流程。首先把 batchnorm 的参数与卷积层的参数融合,然后再对这个参数做量化。
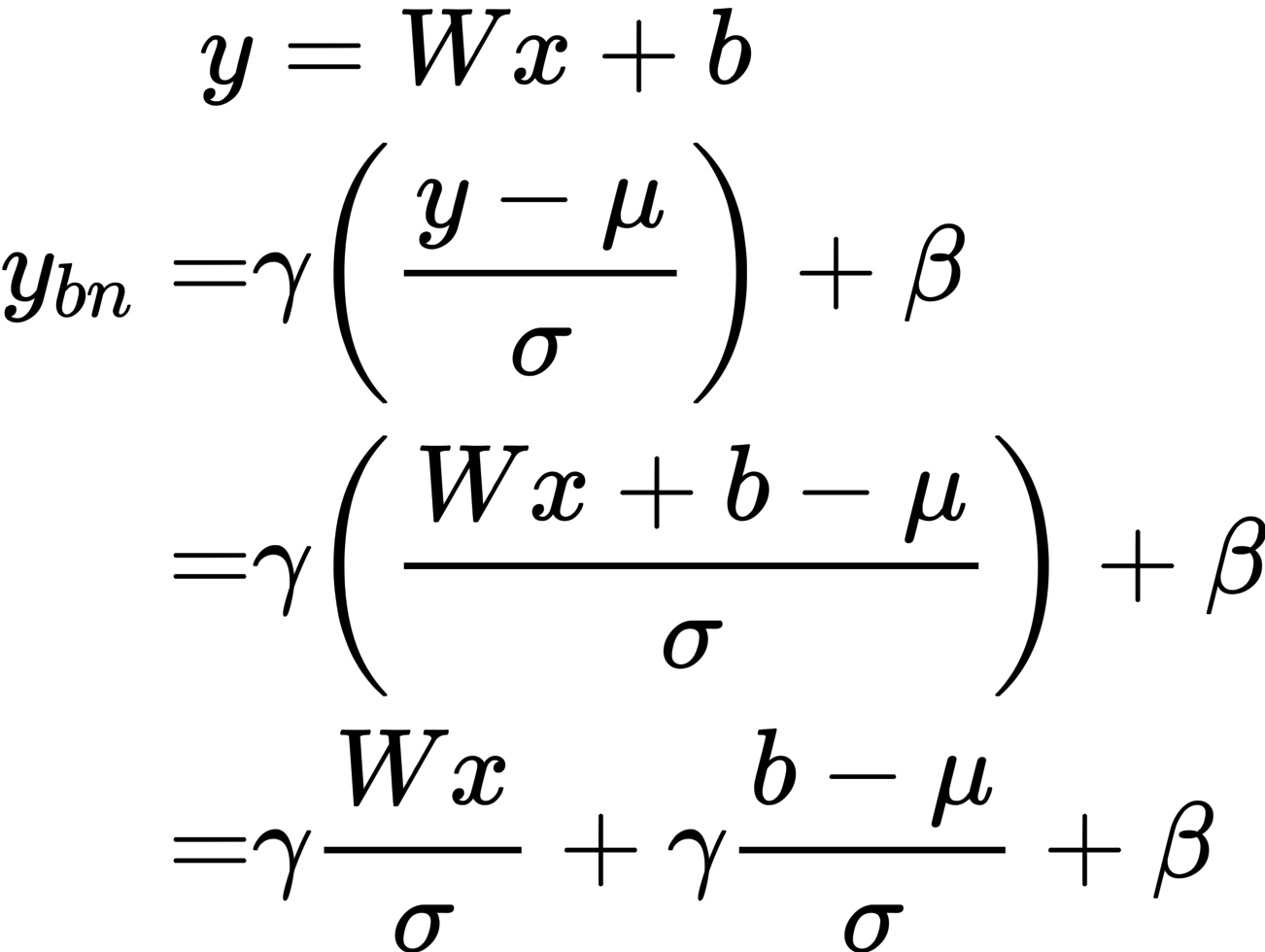
从而可以得到新的卷积权重和偏置: