Faster-rcnn 里的区域生成网络(RPN)
我觉得 RPN 是目标检测领域里最经典也是最容易入门的网络了。如果你想学好目标检测,那一定不能不知道它!今天讲的 RPN 是来一篇来自 CVPR 2017 的论文 Expecting the Unexpected: Training Detectors for Unusual Pedestrians with Adversarial Imposters, 作者在 Faster-rcnn 的 RPN 基础上进行了改进,用于行人检测。
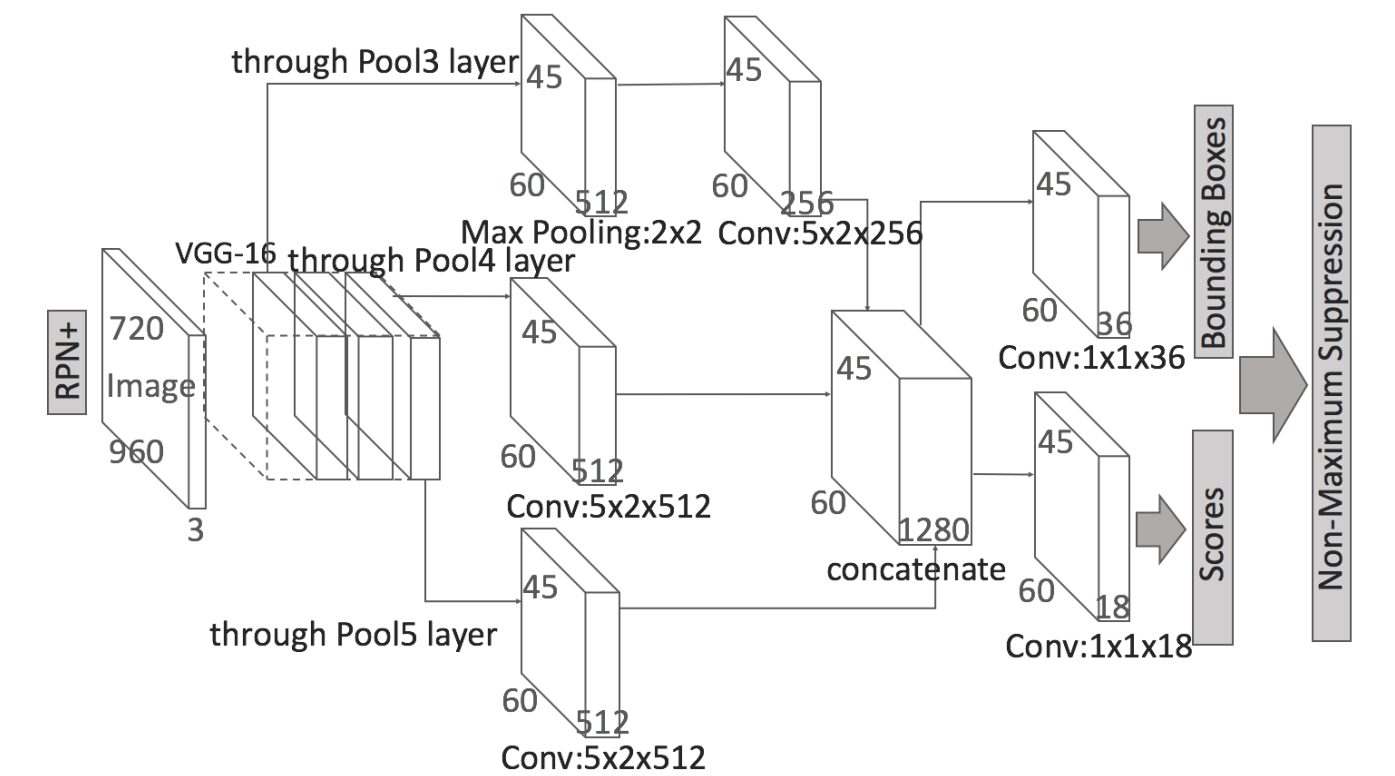
1. 网络结构
上图是 RPN 的网络结构,它采用了 VGG16 网络进行特征提取。从 VGG16 的整体架构来看,作者为了提高 RPN 在不同分辨率图片下的检测率,分别将 Pool3 层、Pool4 层和 Pool5 层的输出进行卷积和融合得到了一个 45 x 60 x 1280 尺寸的 feature map。最后将这个 feature map 分别输入两个卷积层中得到 softmax 分类层与 bboxes 回归层。
2. Anchor 机制
目标检测其实是生产很多框,然后在消灭无效框的过程。生产很多框的过程利用的是 Anchor 机制,消灭无效框则采用非极大值抑制过程进行处理。RPN 网络输入的图片为 720 x 960,输出的 feature map 尺寸为 45 x 60,由于它们每个点上会产生 9 个 anchor boxes,因此最终一共会得到 45 x 60 x 9 个 anchor boxes。
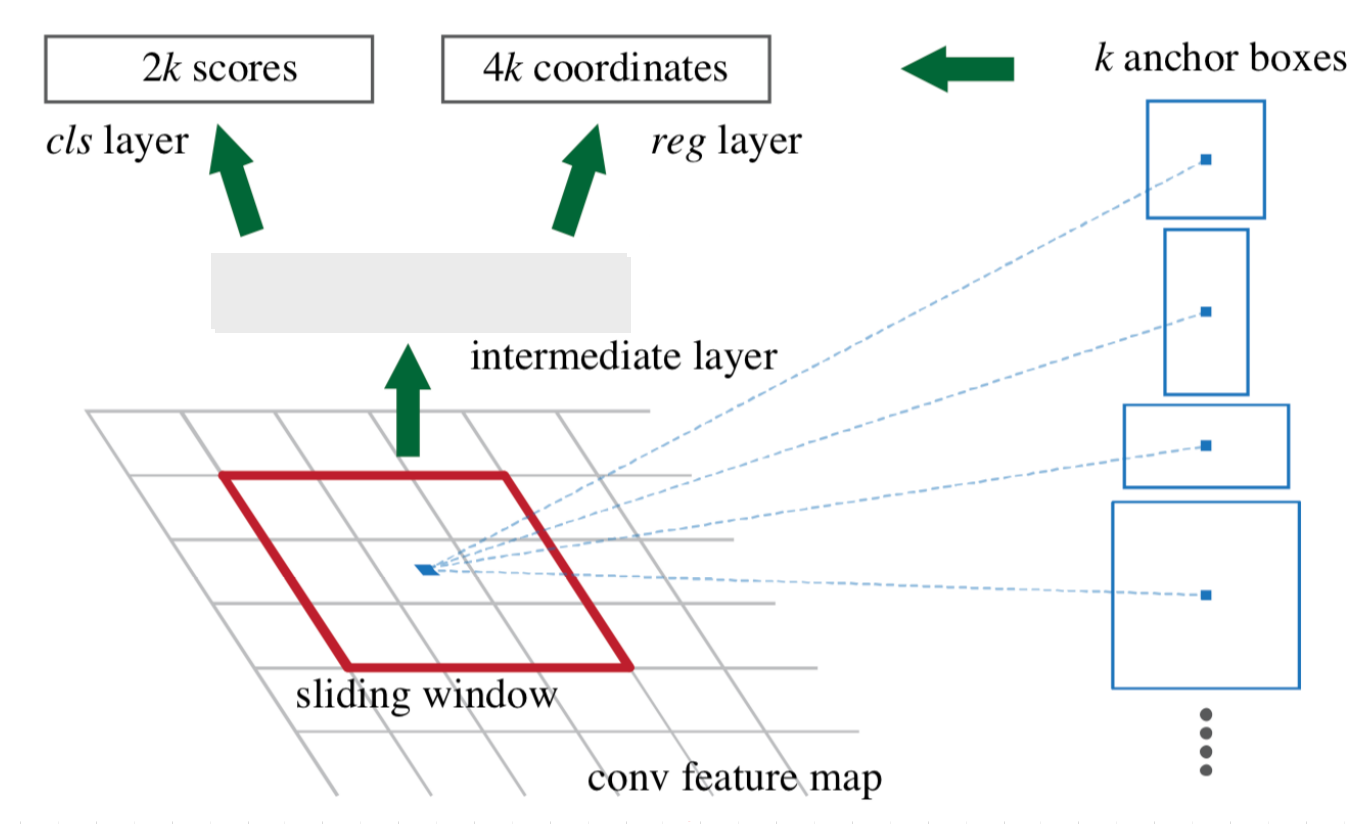
直接利用这些 anchor boxes 对真实框进行预测会有些困难,因此作者采用了 anchor boxes 与 ground-truth boxes 的偏移量机制进行回归预测。

x, y, w, h 分别表示 boxes 的中心坐标和宽高;变量 x, x_{a}, x^{*} 则分别代表预测框,anchor 框和 ground-truth 框的中心坐标 x
def compute_regression(box1, box2): |
3. 损失函数
RPN 的损失函数和 YOLO 非常像,不过从发表论文时间顺序来看,应该是 YOLO 借鉴了 RPN 。在 Faster-rcnn 论文里,RPN 的损失函数是这样的:
- 为了训练 RPN, 我们首先给每个 anchor boxes 设置了两个标签,分别为 0: 背景, 1: 前景;
- 与 ground-truth boxes 重合度 (iou) 最高的那个 anchor boxes 设置为正样本;
- 只要这个 anchor boxes 与任何一个 ground-truth boxes 的 iou 大于 0.7,那么它也是一个正样本;
- 如果 anchor boxes 与所有的 ground-truth boxes 的 iou 都小于 0.3, 那么它就是一个负样本,表示不包含物体;
- 在前面这几种情况下,已经能够产生足够多的正、负样本了,剩下的则既不是正样本,也不是负样本,它们不会参与到 RPN 的 loss 的计算中去。
在我的代码 demo.py 里将正负样本都可视化出来了,大家只要配置好 image 和 label 的路径然后直接执行 python demo.py 就可以看到以下图片。

在上图中,蓝色框为 anchor boxes,它们就是正样本,红点为这些正样本 anchor boxes 的中心位置,黑点表示的是负样本 anchor boxes 的中心位置。从图中可以看出:在有人的区域,正样本框的分布比较密集,并且红点都在人体中心区域;而在没有人的区域则布满了黑点,它们表示的是负样本,都属于背景。
在前面讲到,RPN 网络预测的是 anchor boxes 与 ground-truth boxes 的偏移量,那如果我们将这些正样本 anchor boxes 的偏移量映射回去的话:
=> Decoding positive sample: 20, 20, 0 |

你会发现,这就是 ground-truth boxes 框(绿色框)和物体中心点(红色点)的位置。事实上,RPN 的损失是一个多任务的 loss function,集合了分类损失与回归框损失,它们两者之间的优化可以通过 λ 系数去实现平衡。

初次看这个损失函数有点迷,它其实是一个 smooth-L1 损失函数, 它的优点在于解决了 L1 损失函数在 0 点附近的不可导问题,而且相比于 L2 损失函数而言,它在训练初始阶段的梯度回传会更加稳定。如下图所示,正负样本都会参与到分类损失的反向传播中去(因为你需要告诉网络什么是正样本和负样本),而回归框的损失只有正样本参与计算(只有正样本才有回归框损失,负样本作为背景是没有回归框损失的)。

其中:

def compute_loss(target_scores, target_bboxes, target_masks, pred_scores, pred_bboxes): |
4. k-means 造框
如果 Anchor boxes 的尺寸选得好,那么就使得网络更容易去学习。刚开始我以为反正网络预测的都是 Bounding Boxes 的偏移量,那么 Anchor boxes 尺寸就没那么重要了。但我在复现算法和写代码的过程中发现,看来我还是太年轻了。我使用的是 synthetic_dataset 数据集进行训练,该数据集里所有检测的目标都为 “person”,假如我直接用作者论文里的原始 anchor,那么得到的正样本为如下左图;而如果我使用 k-means算法对该数据集所有的 ground-truth boxes 进行聚类得到的 anchor,那么效果就如下右图所示,显然后者的效果比前者好得多。
| 论文原始 anchor | k-means 的 anchor |
|---|---|
 |
 |
不仅如此,事实上一些其他超参数也会影响正负样本的分布情况,从而直接影响到网络的学习过程。所有这些事实都告诉我们,学习神经网络不能靠从网上看一些浅显的教程就够了的,关键还得自己去多多看源码并实践,才能成为一名合格的深度学习炼丹师。
| pos_thresh=0.2, neg_thresh=0.1 | pos_thresh=0.7, neg_thresh=0.2 |
|---|---|
 |
 |
最后在测试集上的效果,还是非常赞的! 训练的 score loss基本降到了零,boxes loss 也是非常非常低。但是由于是 RPN 网络,所以我们又不能对它抱太大期望,不然 Faster-RCNN 后面更精确的回归层和分类层意义就不大了。按照对这个算法的理解,我用 TensorFlow 对它进行了复现,感兴趣的话可以看看这里。
参考文献
- [1] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, CVPR 2016
- [2] Shiyu Huang. Expecting the Unexpected:Training Detectors for Unusual Pedestrians with Adversarial Imposters, CVPR 2017