批量归一化层(Batch Normalization)
通常来说,数据标准化预处理对于浅层模型就足够有效了。但随着模型训练的进行,当每层中参数更新时,靠近输出层的输出容易出现剧烈变化。这令我们难以训练出有效的深度模型,而批量归一化(batch normalization)的提出正是为了应对这种挑战。
1. BN 来源
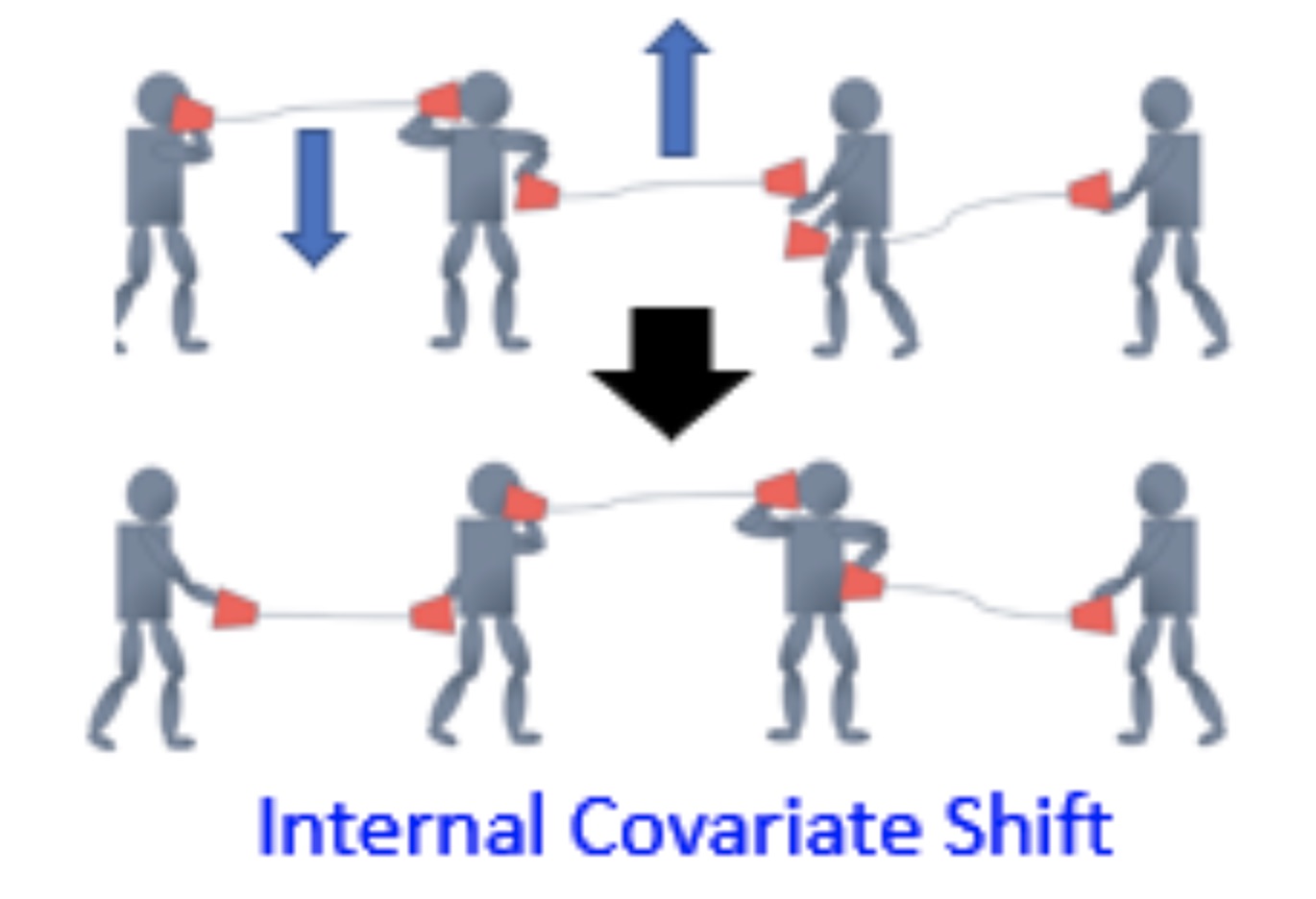
在机器学习领域中,满足一个很重要的假设,即独立同分布的假设:就是假设训练数据和测试数据是满足相同分布的,这样通过训练数据获得的模型就能够在测试集获得一个较好的效果。而在实际的神经网络模型训练中,隐层的每一层数据分布老是变来变去的,这就是所谓的 “Internal Covariate Shift”。
在这种背景下,然后就提出了 BatchNorm 的基本思想:能不能让每个隐层节点的激活输入分布固定下来呢?
BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化(Whiten)操作的话 —— 所谓白化,就是对输入数据分布变换到 0 均值,单位方差的正态分布 —— 因此 BN 作者推断,如果对神经网络的每一层输出做白化操作的话,模型应该也会较快收敛。
2. 计算过程
首先对小批量的样本数据求均值和方差:
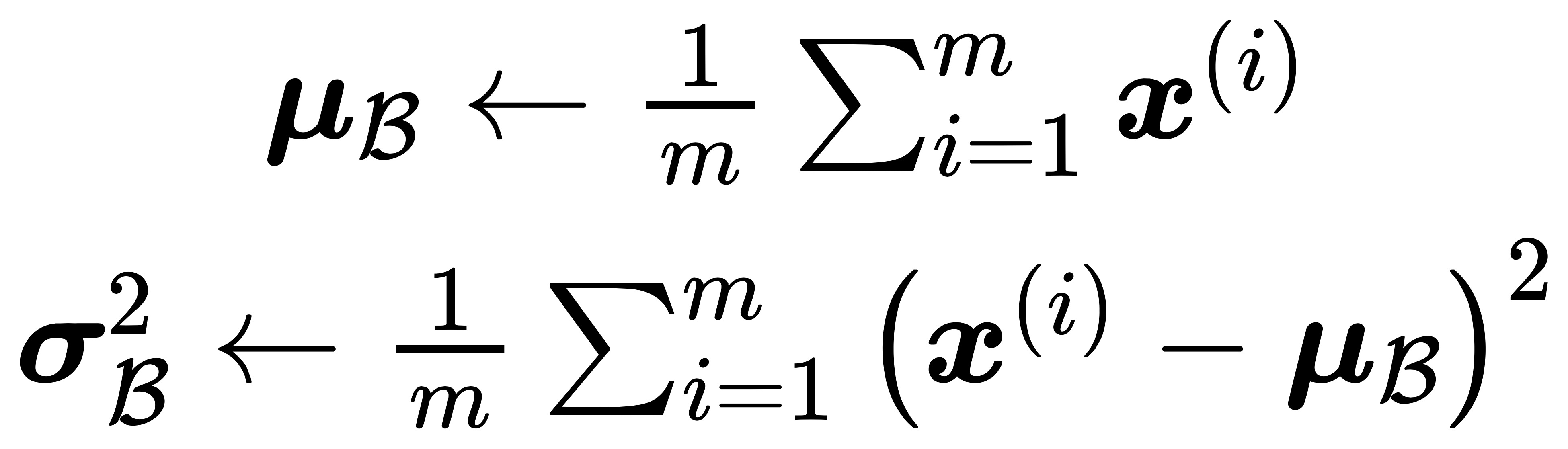
接下来,使用按元素开方和按元素除法对样本数据进行标准化:
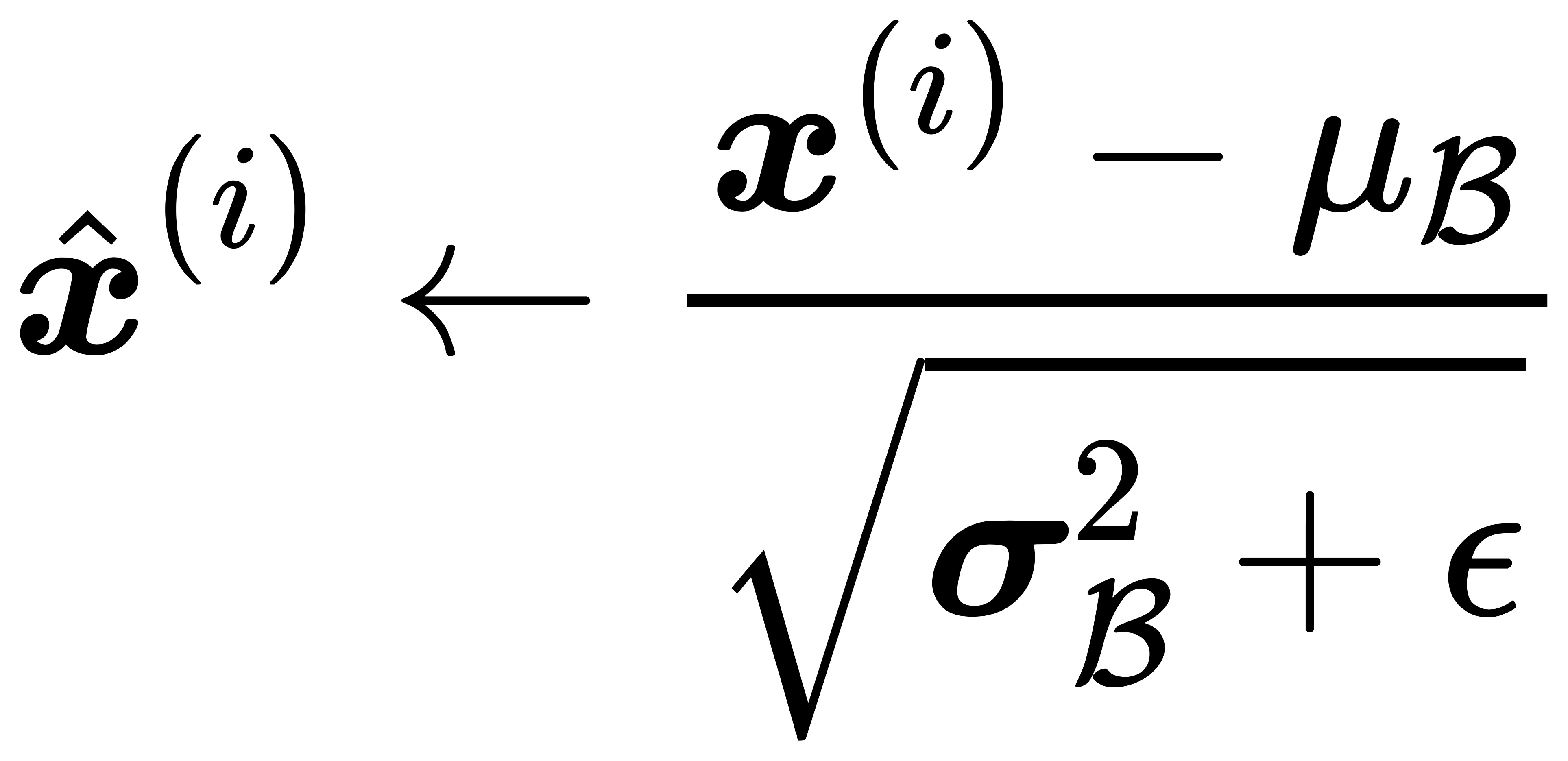

这里 ε > 0是一个很小的常数,保证分母大于 0。在上面标准化的基础上,批量归一化层引入了两个需要学习的参数:拉伸(scale)参数 γ 和偏移(shift)参数 β。这两个参数会把标准正态分布左移或者右移一点并长胖一点或者变瘦一点,从而使得网络每一层的数据分布保持相似。
import d2lzh as d2l |
3. BN 位置
在 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 一文中,作者指出,“we would like to ensure that for any parameter values, the network always produces activations with the desired distribution”(produces activations with the desired distribution,为激活层提供期望的分布)。
| 因此 `Batch Normalization` 层恰恰插入在 conv 层或全连接层之后,而在 relu 等激活层之前。 |
4. BN 优点
- 解决了 Internal Covariate Shift 的问题:模型训练会更加稳定,学习率也可以设大一点,同时也减少了对权重参数初始化的依赖;
- 对防止 gradient vanish 有帮助:一旦有了 Batch Normalization,激活函数的 input 都在零附近,都是斜率比较大的地方,能有效减少梯度消失;
- 能有效减少过拟合:据我所知,自从有了 Batch Normaliztion 后,就没有人用 Dropout 了。直观的理解是:对网络的每一层 layer 做了 BN 处理来强制它们的数据分布相似,这相当于对每一层的输入做了约束(regularization)。
参考文献
- [1] 李沐,动手深度学习. 2019.9.12
- [2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift