CornerNet:Detecting Objects as Paired Keypoints
CornerNet 是一种用于目标检测的新方法,它使用单个卷积神经网络将物体的边界框检测为一对关键点,即左上角和右下角。 通过这种新思路,它摆脱了以往目标检测中使用的 anchor-base 机制,设计了一种新的池化方式 —— 角点池化(corner pooling),可以帮助网络更好地定位角点。实验表明,CornerNet 在 MS COCO 数据集上到了 42.2% 的 AP 值,碾压了当时所有的 one-stage 检测算法。

1. CornerNet 介绍
现在基于 anchor-base 机制的目标检测算法的思路为:将一张图片下采样为低分辨率的特征图,在特征图的每个像素点上放置一些不同大小和宽高比的 anchor,然后让这些 anchor 框与 ground-truth 框进行响应并预测出对应的偏移量。anchor 的本质其实是候选框,由于目标的形状和位置具有多样性,因而 anchor 的数量往往会被设置得非常庞大从而保证足够多的 anchor 能与 ground-truth 框重叠。但是这也带来了以下两个缺点:
- 需要大量的 anchor(例如 DSSD 需要 40K 个,RetinaNet 需要 100K 个),大量的 anchor 中其实只有少部分 anchor 和 ground-truth 相重合,其他则是负样本,这就造成了正负样本不均衡的局面。
- anchor 框引入了许多超参,并且需要进行细致设计。包括 anchor 框的数量、尺寸、宽高比例。特别是在单一网络在多尺度进行预测的情况下会变得非常复杂,并且每个尺度都需要独立设计。
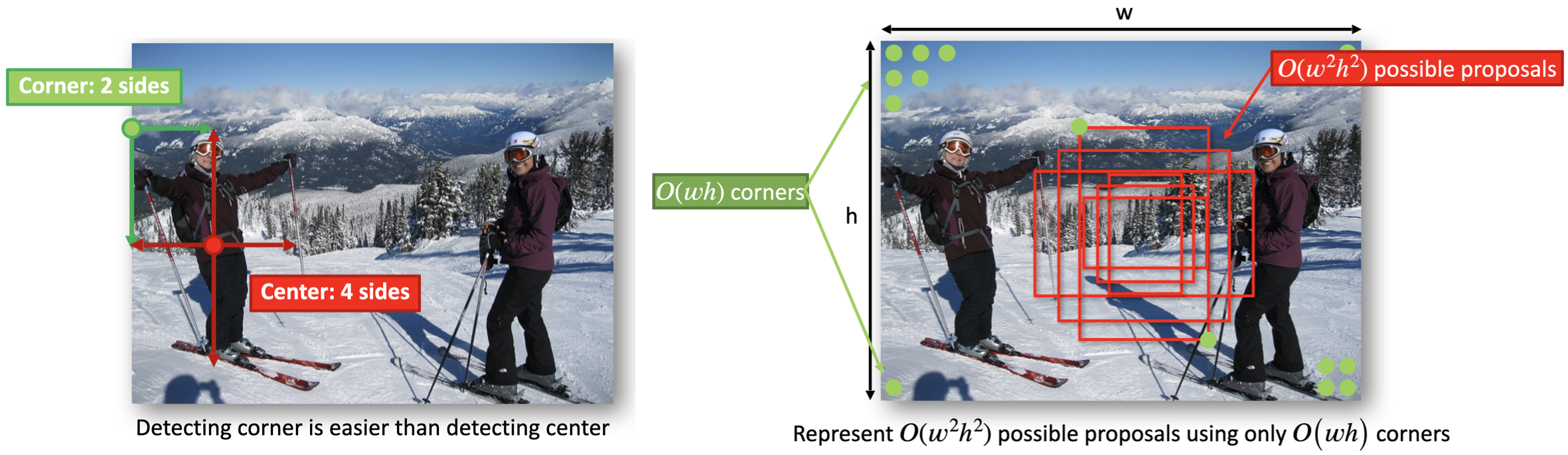
基于上述两点原因,受 keypoint 问题的启发,就想到用关键点检测的思路来处理 detection 问题:只要找到左上角(top-left)和右下角(bottom-right)两个角点,就可以准确框出一个目标了。作者认为预测物体的角点比预测中心更容易,因为预测一个角点只需要物体的 2 个边,而预测中心却需要 4 个边。其次,角点检测的搜索复杂度仅为 O(wh),而 proposal bboxes 的搜索复杂度却为 O(w^2h^2)(这是因为在 proposal bboxes 范围里又检索了一次特征,这导致大量 proposal bboxes 之间的特征存在冗余)。
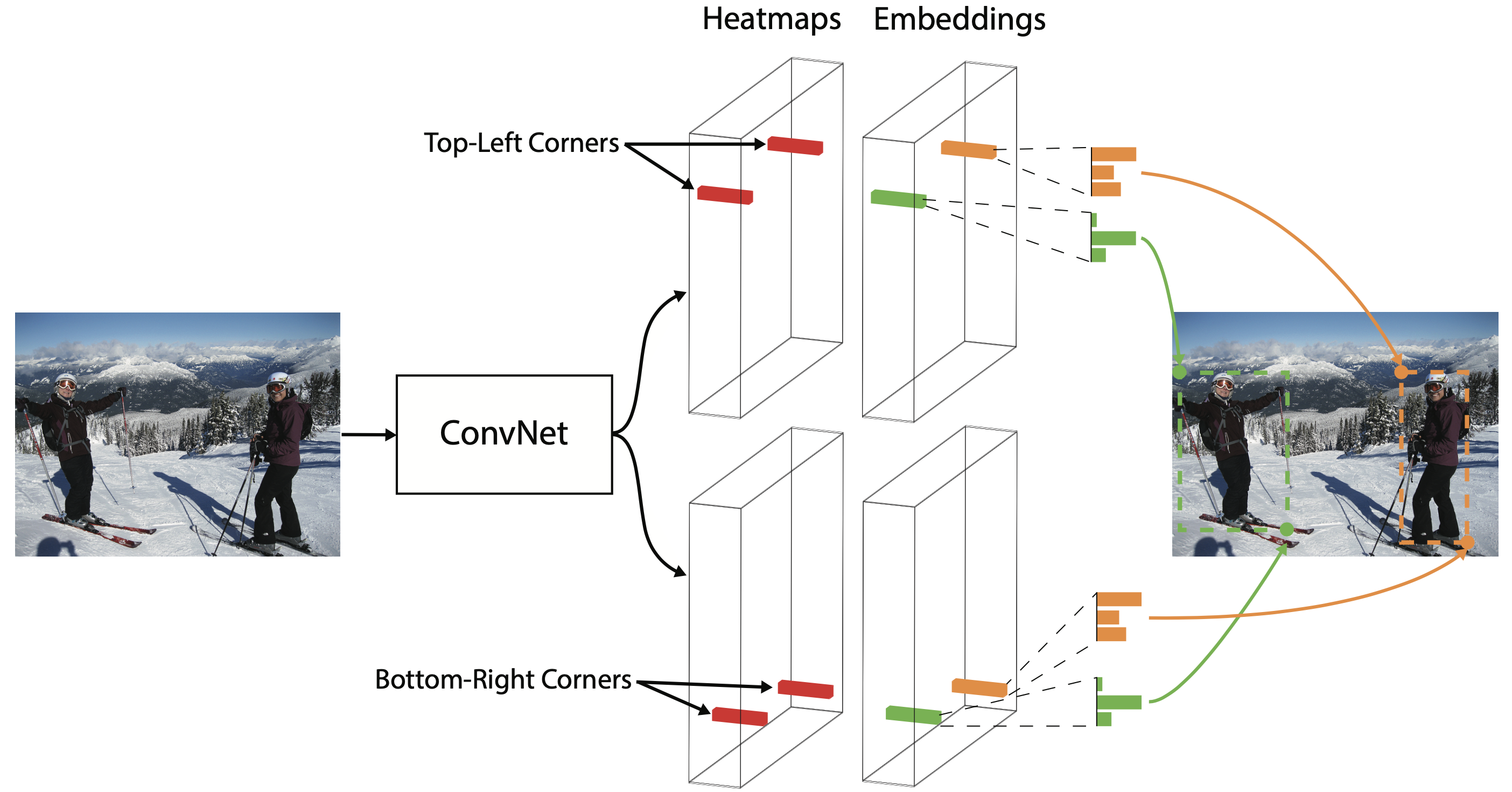
如下图所示:CornerNet 使用一个单一网络来预测所有目标的角点热图(heat map)和 embedding 向量,找出那些最有可能的角点并根据它们之间的 embedding 向量距离来进行分组。
2. 检测角点
2.1 heatmap
CornerNet 会输出两个热图(heat map)分别预测出所有目标的左上角和右下角的位置,每个热图的 shape 为 [C, H, W],其中 C 是目标的类别(没有background channel),H 和 W 分别是高和宽。每个角点都有一个对应的 ground-truth 正位置,其他地方则是负位置,这里并没有对所有对负位置进行相同惩罚。这是因为在一些在离 ground-truth 一定半径范围内的角点,它们仍然能产生与 ground-truth 充分重叠的 bbox。

那么这个半径范围选多大呢,作者是这样说的:通过判断这些角点构成的预测框与 ground-truth 框之间的 iou 大于 t 时计算出半径,在论文里 t 设置为 0.3 。这个半径范围内,惩罚权重的衰减则由一个二维的高斯分布给出。为了减少正负样本不均衡性带来的影响,作者还用了 focal loss 来计算预测热图和真实热图之间的损失。
2.2 location offset
物体的位置精度在下采样时通常会丢失,比如图片上某个像素点 [x,y] 在经过 n 倍下采样后得到新位置为 [floor(x/n),floor(y/n)],floor 表示向下取整。当我们将这个新位置 remap 回原图时会偏离原来的位置,这会严重影响到一些小目标的预测。为了解决这个问题,CornerNet 采用预测位置偏移量(location offset)的方法来对角点位置进行微调。对于位置偏移量的定义,作者是这么定义的:
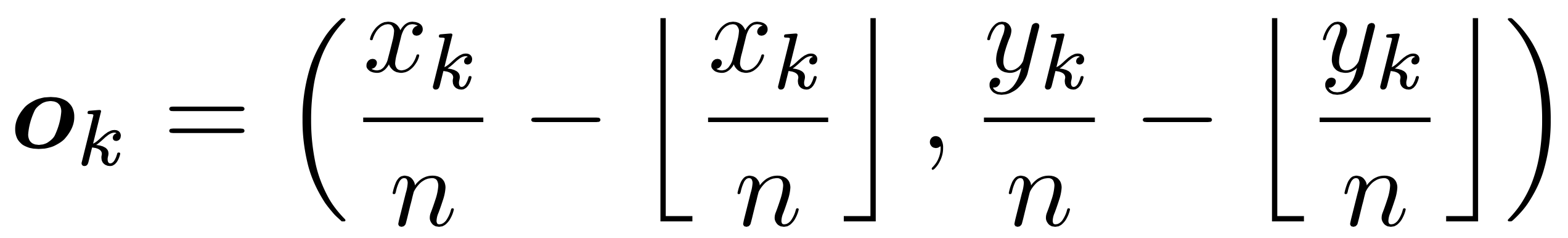
从公式中可以看出,物体角点的精确位置减去其向下取整的位置(其实就是角点左上角最近的网格)就是偏移量。这种方法没什么新奇的,和 YOLOv3 对物体中心点位置预测的思路基本一致。对于偏移量的损失,作者采用了 smooth L1 Loss 函数。
3. 角点成对
前面介绍的角点预测工作都是孤立的,不涉及一对角点构成一个检测框的概念。受 Newell 等人姿态估计工作的启发,可以基于不同角点的 embedding 向量之间的距离来对它们进行关联。embedding 特征图的维度为 [N, H, W],即每个角点都会产生一个 N 维的向量。考虑到 MOT 的数据集一般来说都比较小,ReID 特征的维度不宜过高,文章将 N 设置成了 1,这样 embedding 向量就成了一个标量。
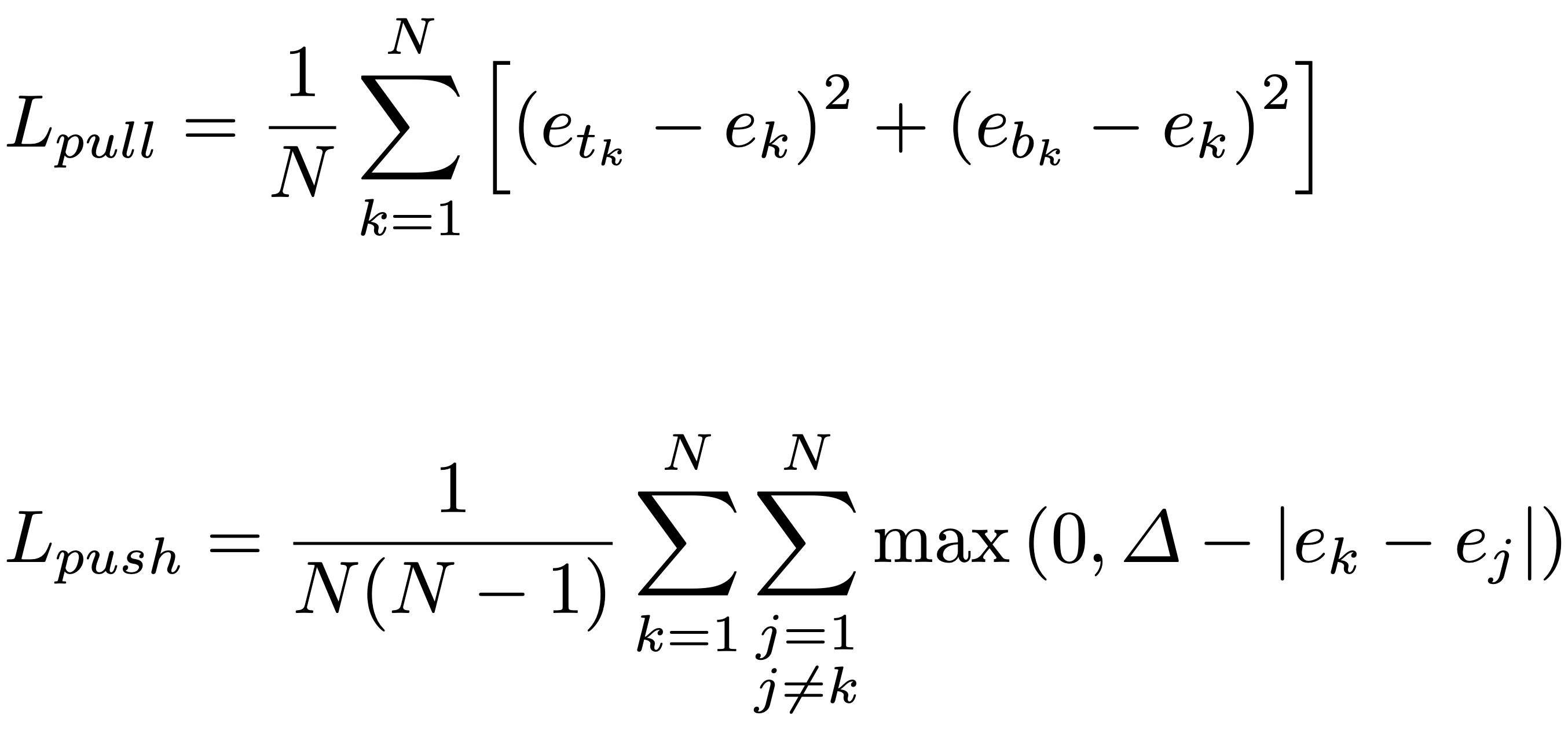
这个向量编码了这个角点对应目标的特征,如果一个左上角和右下角属于同一个目标,那对应的这两个 embedding 向量应该很相似,因而它们之间的距离应该最小。网络在训练时,使用了 push 损失让同一个目标之间的角点距离最小,push 损失让不同目标之间的角点距离最大。
4. Corner Pooling
4.1 角池化介绍
预测框的角点通常在物体范围外,这使得角点附近没有可用的物体特征。例如为了确定像素是否在左上角,我们需要在水平方向上沿着物体的最上边界朝右看,而在垂直方向上沿着物体的最左边界朝下看。因此我们提出了一种角池化(corner pooling)操作,确保在池化过程中能够编码到整个物体的特征。

下面有 2 个输入特征图,宽高分别用 W 和 H 表示。假设接下来要对红点(i,j)做 corner pooling:在纵向上就要计算 (i, j) 到 (i, H) 的最大值,在横向上就要计算 (i, j) 到 (W, j) 的最大值,然后将这两个值相加即可。
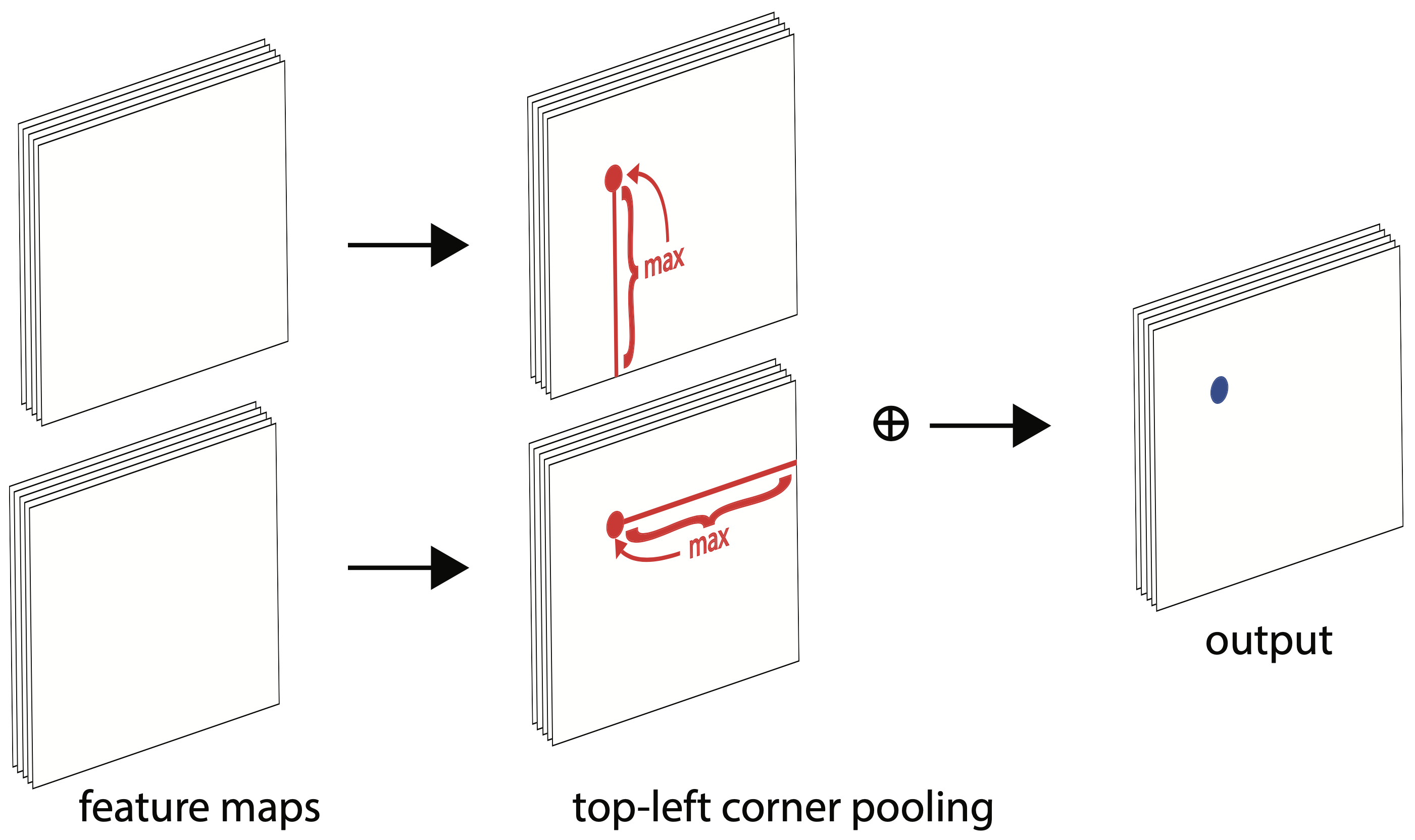
动态规划其实可以减少这个计算的复杂度,我们可以在横向上从右往左、在纵向上从下往上去扫描计算最大值,这样大大减少了复杂度。如下图所示:以 2, 1, 3, 0, 2 这一行为例,最后的 2 保持不变,倒数第二个是 max(0,2) = 2,然后倒数第三个为 max(3,2)=3 …… 依次类推。

4.2 角池化位置
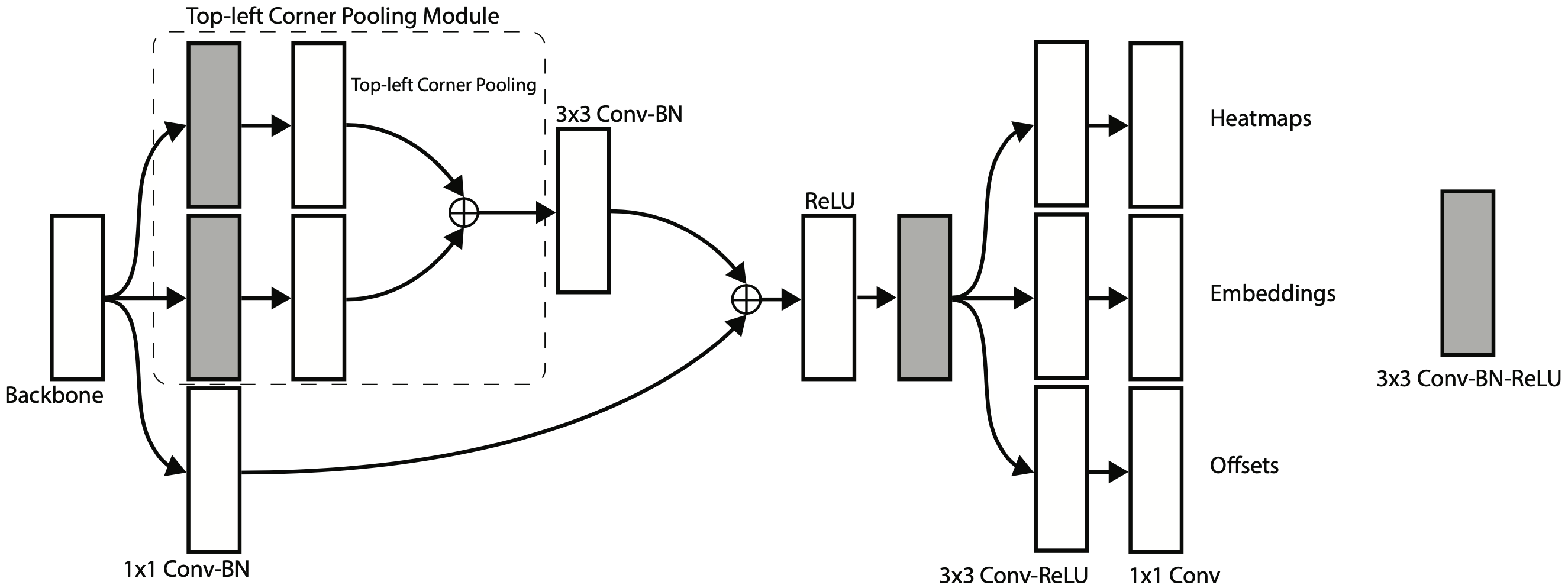
corner pooling 层放在预测模块(prediction module)里,用于预测热图和 embedding 向量。预测模块对何凯明的残差模块做了修改:将第一个 3×3 卷积模块替换为一个 corner pooling 模块,它通过两个具有 128 个通道的 3×3 卷积模块处理来自主干网的特征,然后再应用于 corner pooling 层,接着将特征合并送入 256 个通道的 3×3 Conv-BN 层中并与 short-cut 特征融合,以生成热图、embedding 向量和位置偏移量。